NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2015.12.28
35,623
LinuxサーバーのTCPネットワークのパフォーマンスを決定するカーネルパラメータ- 1編
LinuxサーバーのTCPネットワークのパフォーマンスを決定するカーネルパラメータ- 2編
TIME_WAIT状態のソケットは、利用可能なlocal port数を軽減させて同時に保有できるクライアントソケットの数を制限します。
TIME_WAIT状態のソケットは、いつ発生するでしょうか?
まず、TCPソケットの状態フローを見てみましょう。
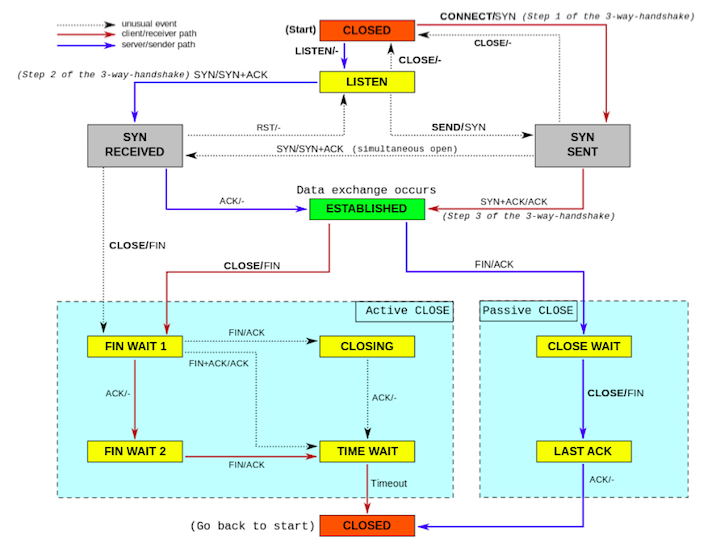
上図から分かるように、active closingするソケットの最後の終着地がTIME_WAITの状態です。
言い換えれば、クライアントソケットであれ、サーバーソケットであれ、close()システムコールを先に呼び出した側(active closing)が最終的にそうなります。
TIME_WAIT状態では、RFC793の定義通りなら2MSL(Maximum Segment Lifetime)、すなわち2分間待機することになります。ところが、実際はほとんどのOSは、最適化のため1分程度をTIME_WAIT状態で待機するように実装されています。Linuxもこの時間を1分で規定しており、変更できません。(カーネルコードの定数として定められています。)
Googleで検索できる一部の文書では、net.ipv4.fin_timeoutを変更すると、TIME_WAITで待機する時間を変更できると紹介しています。net.ipv4.fin_timeoutは、FIN_WAIT_2の状態に停留できる最大時間を設定します。(RFCは、TIME_WAIT状態以外では別途timeoutを定義していませんが、大半のシステムでは、最適化のため別途timeout時間を置いています。)現実世界では、FIN_WAIT_2に留まるソケットは非常に珍しく、自然とTIME_WAIT状態に遷移されるので、設定値はデフォルトのままでも大きな問題にはなりません。
ここで強調したいのは、TIME_WAIT状態は悪い状態ではないということです。
ソケットの、極めて正常なライフサイクル内の1つの状態であり、ソケットのgracefully shutdownを保証する不可欠な要素です。
まず、Webサーバーを例に挙げて、TIME_WAIT状態のソケットを確認してみましょう。
HTTP keepaliveオプションを使用しないWebサーバーがあるとします。
このサーバーで次のようなコマンドを使うと、現在のTIME_WAIT状態のソケットを確認できます。
$ netstat -n -t | grep 'TIME_WAIT' Proto Recv-Q Send-Q Local Address Foreign Address State tcp6 0 0 10.77.57.106:10080 10.77.94.26:37901 TIME_WAIT tcp6 0 0 10.77.57.106:10080 10.77.94.26:37900 TIME_WAIT tcp6 0 0 10.77.57.106:10080 10.77.94.26:37905 TIME_WAIT tcp6 0 0 10.77.57.106:10080 10.77.56.86:41811 TIME_WAIT tcp6 0 0 10.77.57.106:10080 10.77.56.82:48168 TIME_WAIT
上の例は、サーバーのポート10080を使用するWebサーバーで発生したTIME_WAIT状態のソケットです。
HTTP 1.1ではスペック上、誰が最初にソケットを切断するか定義していません。しかし一般的な実装では、keepaliveの設定を使用しない場合は、サーバーからクライアントにデータを転送した後、すぐにclose()システムコールを呼んで接続を切断します。したがって、上記のようにサーバーにTIME_WAIT状態のソケットが残るようになります。
ではこの場合(サーバーソケットでTIME_WAITが発生した場合)、TIME_WAITソケットが多くなることは問題でしょうか?
結論から言えば、大きな問題にはなりません。
TIME_WAIT状態のソケット数の制限を確認してみましょう。
net.ipv4.tcp_max_tw_bucketsカーネルパラメータにこの値が設定されています。
次のようなコマンドで、設定値を確認できます。
$ sysctl net.ipv4.tcp_max_tw_buckets net.ipv4.tcp_max_tw_buckets = 65536
このシステムでは、TIME_WAIT状態のソケットは、同時に65,536個存在することができます。
もしTIME_WAIT状態のソケット数がこれより多くなると、どうなるでしょうか?
TIME_WAIT状態のソケットは、上記で設定された値よりも多くなることができません。すでにこの設定値だけのTIME_WAIT状態のソケットがあった場合、TIME_WAIT状態に遷移すべきソケットはもはや待機されず、破壊(destroy)されてしまいます。つまり、gracefully shutdownをせずに閉じてしまい、サーバーアプリケーションはこれを認知できません。このような場合、一般的にソケットは破壊され、/var/log/messagesのようなところに、次のようなログメッセージが残ります。
TCP: time wait bucket table overflow
このように破壊されたソケットは、TCPのgracefully shutdownの原則に反しますが、サーバーのパフォーマンスや容量に大きな影響を与えません。しかし、ソケットがgracefully shutdownになっていないので、サーバーからクライアントへ送り出されていないデータも消えてしまいます。この場合、クライアントでは不完全なデータを受信することになります。
したがって、できるだけソケットはgracefully shutdownにする必要があり、リクエスト量が多いサーバーでは、この値を適切に上げておいた方がよいでしょう。メモリ量も重要なtrade-off要因ですので、比較的メモリ量が十分なサーバーであれば、適当に上げても問題ありません。
次のようなコマンドで適量増加します。
$ sysctl -w net.ipv4.tcp_max_tw_buckets="1800000"
ここでまた1つ疑問があります。特定のforeign addressとforeign portを持つソケットがTIME_WAIT状態にあるとき、同じアドレスとポートでクライアントから接続要請があると、どうなるでしょうか?
RFC 1122では、同じアドレスとポートを使用するTIME_WAIT状態のソケットがあっても、SYNを受信すると、このソケットを再利用するようになっています。そのために、別途設定しなくても問題になることはありません。
ここまでを整理すると、サーバーソケットのみのサーバーでは、TIME_WAITソケットが多くなっても、パフォーマンスと容量の面では問題がありません。このようなタイプのサーバーの場合、TIME_WAITソケット数にそれほど敏感になる必要はありません。ただし、TCPソケットは、なるべくgracefully shutdownになる必要がありますので、net.ipv4.tcp_max_tw_bucketsのカーネルパラメータを適当に上げた方がよいでしょう。
大規模なサービスでは、Webサーバーであっても他のサーバーに問い合わせる場合があります。この場合、サーバーは別サーバーのクライアントとなり、TIME_WAIT状態のソケット数がパフォーマンスに影響を与える可能性があります。
あるサーバーが別サーバーに質疑するとき、別途connection poolを置かずにHTTP RESTful APIで質疑した、と仮定しましょう。そして、このとき、HTTP keepaliveは使用しないと仮定します。この形態は一般的にもよく使われていますね。通常、TCP keepaliveの場合、L4スイッチによって無用の長物になるので大抵は使用されません。
このとき、TIME_WAIT状態のソケット数が、local portを先取りして生成できるクライアントソケットの数を制限します。言い換えれば、他のサーバーに同時照会できる接続数を減らします。最悪の場合、他のサーバーで1分以内のクエリ数が保有できるephemeral port数より多いときは、HTTP接続の時点で要請は失敗します。
不要になったソケットを閉じただけなのに、このために新しいソケットを作成できないのは適当なのでしょうか?
これを解消するには大きく4つの方法があります。
(1)アプリケーションでconnection poolを使用
パフォーマンスと柔軟性の面で最も推奨している方法で、アプリケーションを修復します。
(2)TW_REUSEオプションを使用
使用できるlocal port数が不足している場合、現在のTIME_WAIT状態のソケットのうち、プロトコル上、使っても問題ないと思われるソケットを再利用します。
(3)TW_RECYCLEオプションを使用
TIME_WAIT状態にとどまる時間を変更して、TIME_WAIT状態のソケット数を減らします。1分の代わりにRTO(Retransmission Timeout)の時間だけTIME_WAIT状態に停留する時間が軽減されますが、Linuxでは200msまでの時間を与えることができます。(最小RTOが200ms)
(4)Socket lingerオプションで非常に短時間をパラメータとして使用
FINの代わりにRSTを送信するように誘導し、このときソケットを破壊してソケットがTIME_WAIT状態にとどまらないようにします。
相対的に、TW_RECYCLE, socket lingerオプションは、TW_REUSEよりも過激な方法なので、あまりお勧めしません。
TW_REUSEを使用するには、net.ipv4.tcp_tw_reuseのカーネルパラメータを設定する必要があります。上で紹介したように、TW_REUSEは、特定の状況でのみTIME_WAIT状態のソケットを再利用します。この判断ロジックには、TCP timestampという拡張オプションを使用します。そのため、TW_REUSEオプションを有効にするには、まずTCP timestampオプションも有効にする必要があります。
TCP timestampを使用すると、TIME_WAIT状態のソケットに通信が行われた最後の時間(timestamp)を記録できます。
TW_REUSEオプションを有効にした状態で、クライアントソケットを作成すると、TIME_WAIT状態のソケットのうち、現在のtimestampよりも確実に小さい値のtimestampを持つソケットは再利用(reuse)ができます。一般的に、Linuxではtimestampの単位は秒なので、TIME_WAIT状態に遷移してから1秒後のソケットは再利用できるようになります。
次のようなコマンドでTW_REUSEオプションを有効にできます。
$ sysctl -w ipv4.tcp_timestamps="1" $ sysctl -w net.ipv4.tcp_tw_reuse="1"
注意することは、TW_REUSEオプションは、通信を行う双方でTCP timestampオプションが設定されていると有効になるということです。どちらか一方でもTCP timestampオプションが有効になっていなければ、TIME_WAIT状態のソケットを再利用することはできません。
TCPでは、sequence numberでパケットの順序(ordering)を判別します。この値は32ビットのunsigned int型で、0から約40億までの表現範囲を持っています。ここで、非常に高速なネットワーク環境があると仮定してみよう。さらに、receiverはこのネットワークより、少し遅い処理速度を持っていると仮定します。
このような状況で、sequence numberはネスト(wrapping)ができます。
例えば、ある瞬間でreceiverは任意のsenderから100というsequence numberを持つパケットを受けたとします。その後、receiverは100以上のsequence numberを持つパケットを期待するでしょう。
ここで、receiverは瞬く間に40億以上のパケットを受信したとします。ところが、receiverはまだこのパケットを忘れていません。NIC、すなわちネットワークアダプタにより受信しましたが、まだカーネルのTCP stackでは、このパケットを開いていない状態です。(10Gのネットワークであれば、不可能なことではありません。)このとき、最後の頃に受信したパケットのsequence numberはunsigned int型の表現範囲のため、必須でoverflowされたはずです。便宜上、TCP stackが見るべきパケットのsequence numberが、101〜4,294,967,296まで、そして以降overflowになって、0〜200だと仮定しましょう。
receiverは100以上のsequence numberを期待していましたが、これより小さな数である0〜100のsequence numberを受けた状況です。手順(ordering)に反するので、このパケットは新たに受信したパケットにも関わらず捨てられます。(silently dropped)
またこの場合、重複したsequence numberのパケットも存在することになります。例えば、sequence numberが101であるパケットが2つ存在したとしましょう。ネットワーク上のパケットは、reorderingできることを踏まえて、この2つのパケットの前後関係は確定することができるでしょうか?
当然確定できません。TCP stackの実装によって異なりますが、どちらか一方のパケットは捨てられるでしょう。
このような問題、つまり、wrapped sequence number問題を解決するため、RFC 1323ではPAWS(Protection against Wrapped Sequence Numbers)という方法を提案しています。これは、reorderingを判別する要素にsequence numberだけでなく、timestamp値を使用するというものです。PAWSが実装されたTCP stackは、timestampが含まれているパケットを受信すると、このtimestampを記録しておいてconnectionごとに管理します。
名前から推測できるように、timestampは一方向に増加する値です。一般的に、timestampはミリ秒(millisecond)単位でsystem clockから使用する場合が多いです。ところで、senderとreceiver間の通信では、timestamp値が同期(synchronization)されているでしょうか?
結論から言えば、その必要はありません。timestampは一方向に増加する値であればよく、system clockと連動する必要がありません。論理的には、sequence numberのhigh orderとして使用されるからです。
timestampを置くと、上記のような例(短時間でsequence numberがoverflowされる状況)で新たに受信したパケットを捨てる問題が解決できます。sequence numberが重畳(wrap)されたとしても、timestampはより高い値であるため、新たに受信したパケットと認識することができます。(上記のようにsequence numberのhigh orderと考えると容易に理解できるでしょう。)
LinuxでTCP timestampを使用するには、net.ipv4.tcp_timestampsというカーネルパラメータを1に設定する必要があります。
次のようなコマンドから、現在の設定値を確認できます。
$ sysctl net.ipv4.tcp_timestamps
最新の一般的なLinuxディストリビューションでは、デフォルトが有効になっています。
ちなみに、正しく動作するには、sender/receiverのすべてを有効にする必要があります。
TW_REUSEオプションより過激な方法は、TW_RECYCLEオプションを使用することです。
TW_RECYCLEはソケットがTIME_WAIT状態にとどまる時間をRTOだけに再定義することになります。
RTO時間はRTTに影響を受け、一般的に1分よりは短いです。
次のようなコマンドでTW_RECYCLEオプションを有効にできます。
$ sysctl -w ipv4.tcp_timestamps="1" $ sysctl -w net.ipv4.tcp_tw_reuse="1" $ sysctl -w net.ipv4.tcp_tw_recycle="1"
TW_RECYCLEオプションを有効にするには、まず、TCP timestampとTW_REUSEを有効にする必要があることに注意しましょう。
しかし、TW_RECYCLEはあまりお勧めしません。
クライアントがNAT環境である場合、一部のクライアントからのSYNパケットが失われる可能性があるからです。
つまり、TW_RECYCLEを使用すると、一部のTCP接続要請は失敗します。
なぜこのような現象が発生するのでしょうか?
TW_RECYCLEを使用するとき、TIME_WAIT状態の待機時間が極めて短くなり、TIME_WAITに残っているソケットがほとんどありません。(もちろん、peerがtimestampを使わなければ残ります。)しかし、カーネルはなるべくTIME_WAIT状態のソケットがあるかのように行動しようとします。ソケットのgracefully shutdownを保証するためですね。
例えば、あるソケットがactive closingになったとしましょう。TIME_WAIT状態で非常に短い時間とどまった後、削除されます。やがて同じforeign address/portから接続要請が届き、新しい接続が結ばれます。
このとき、sequence numberが逆転したパケットが届いたとします。
ではこのパケットが、以前に切断されたソケットのものか、今接続が結ばれたソケットのものか、分かるでしょうか?このような場合はどうすればよいでしょうか。
これを解決するため、TW_RECYCLEオプションを使ってTIME_WAIT状態のソケットがあるようにコピーをとります。ロジックを簡単に説明しましょう。
(1)TIME_WAIT状態に入ると、他の構造体に現在のソケットのforeign addressとtimestamp値を記録します。
(2)該当foreign address/portのパケットがくると、(1)の過程で認知しているtimestampと対照し、より小さなtimestampを捨てます。
(3)この構造体に格納された値は、元のTIME_WAIT状態に滞在する時間だけ(つまり1分)維持されます。
つまり、timestampが逆転されたパケットは捨てられます。
ところで、上記のようにtimestampはpeerにあまり同期されていません。NATを使用しているクライアントは、サーバーの立場では、すべて同じアドレスを使用しているように見えます。送信するパケットのtimestampは、クライアント別に異なる値を持つことができます。そのため、既存ソケットが最後に記録したパケットのtimestamp値が新たにソケット接続を要請するSYNパケットに含まれているtimestampよりも大きいことが分かります。そして、この場合、上述したように静かに捨てられます。
特にfront-endサーバーでは、TW_RECYCLEオプションを(絶対)使用してはいけません。このサーバーは、主にインターネット上で受信されるクライアントの要請を受けることになるからです。
インターネットのクライアントは、NAT環境である確率が大きいです。3G/LTEなどのモバイルネットワーク環境は一種の巨大なNAT環境です。中国と同様にIPアドレスが足りない環境では、NATをたくさん使用します。この場合、多数のクライアントからサーバーへ接続できない障害が発生することがあります。
TIME_WAIT状態のソケットを減らすもう1つの極端な方法は、ごく短い時間(例えば0秒)でlingerオプションを有効にすることです。ソケット当たりに設定できるオプションですが、デフォルト設定は無効になっています。
そもそもTCPソケットはclose()を呼び出すとすぐに返却されます。ソケットを閉じる実際の動作(まだソケットバッファに残っているデータを送るとか、FIN/ACKを送るとか)は、カーネルによって進行されます。このソケットは最終的にTIME_WAIT状態になって与えられた時間(Linuxでは1分)待機します。
lingerオプションはclose()の返還を即時実行せず、つまりnon-blockingに返却せずに、blocking mannerで処理することを意味します。アプリケーションは、close()時、lingerオプションが有効なら与えられたパラメータの時間までblockされます。この間、カーネルはソケットバッファに残っているデータを送ろうと努力します。与えられた時間内にこうした処理が完了すると、すなわち正常処理されたら、一般的な方法と同様にカーネルはFINを送り、ソケットも最終的にTIME_WAIT状態になります。しかし、与えられた時間内に正常処理されなければ、カーネルはFINの代わりにRSTを送り、ソケットは直ちに破壊されます。
TIME_WAIT状態のソケットを減らす極端な方法は、このlingerオプションでblock時間を「0」に設定することです。そうするとclose()時、カーネルは即時にFINの代わりにRSTを送信してソケットを破壊するでしょう。TIME_WAIT状態のソケットも残っていません。
しかし、lingerオプションは、決してTIME_WAIT状態のソケットを除去するためのオプションではありません。データをpeerに完全に伝達(delivery)するために、アプリケーションにより制御を与える1つのオプションに過ぎません。一般的な処理において、ソケットはカーネルによってgracefully shutdownするのが正しいです。
ここまでする背景には、TIME_WAIT状態のソケットを害悪と見做しているからでしょう。
しかし、パケットのreorderingや損失があり得るネットワークの特性上、ソケットはできるだけgracefully shutdownにする必要があります。
ここで繰り返し申し上げることは、TIME_WAIT状態のソケットは大きな害悪ではないということです。ソケットが正常終了される過程なのです。サーバーソケットでは通常、何の問題もありませんし、クライアントのソケットでもTW_REUSEオプションで克服できます。
TW_REUSEオプションが使用不可能な極めて例外的な状況(例えば、timestampを使用しない多数のサーバーとの通信)であっても、TW_RECYCLE, lingerオプションのような極端な処置は避けるべきでしょう。TIME_WAIT状態のソケット数がパフォーマンスのボトルネックであるなら、keepaliveを使用したり、connection poolなどを実装するなど、アプリケーション自体を修正する必要があります。
要約しましょう。
$ sysctl -w net.ipv4.tcp_window_scaling="1" $ sysctl -w net.core.rmem_default="253952" $ sysctl -w net.core.wmem_default="253952" $ sysctl -w net.core.rmem_max="16777216" $ sysctl -w net.core.wmem_max="16777216" $ sysctl -w net.ipv4.tcp_rmem="253952 253952 16777216" $ sysctl -w net.ipv4.tcp_wmem="253952 253952 16777216"
$ sysctl -w net.core.netdev_max_backlog="30000" $ sysctl -w net.core.somaxconn="1024" $ sysctl -w net.ipv4.tcp_max_syn_backlog="1024" $ ulimit -SHn 65535 `
$ sysctl -w net.ipv4.tcp_max_tw_buckets="1800000" $ sysctl -w ipv4.tcp_timestamps="1" $ sysctl -w net.ipv4.tcp_tw_reuse="1"
すべてのワークロードを満足させる設定値はありません。上記のパラメータの値は、本文のサンプル値をそのまま移したものに過ぎません。より精密にチューニングするには、サーバーアプリケーションの特性(ワークロード)について、より詳しく理解する必要があります。
Q1)最近のサーバーでは、cubic方式をよく使います。以前よく使われていたrenoで、カーネルコンパイルなしに変更して使用できますか?もし可能なら、どのようなアルゴリズムを提供しているか知りたいです。
A1)
現在、ご利用いただけるcongestion control algorithmリストは、次のように確認できます。
$ cat /proc/sys/net/ipv4/tcp_available_congestion_control (OR) $ sysctl net.ipv4.tcp_available_congestion_control
例えば、ubuntu 14.04.2 LTSなら、基本的にcubic、renoが搭載されています。
次のように、congestion control algorithmを変更できます。
$ echo "reno" > /proc/sys/net/ipv4/tcp_congestion_control (OR) $ sysctl -w net.ipv4.tcp_congestion_control="reno"
tcp congestion control algorithmはpluggable kernel moduleになっています。
上記のほか、利用可能なリストを探すには、次のようなコマンドが使えますよ。
ls /lib/modules/`uname -r`/kernel/net/ipv4/
tcp_vegas.ko、tcp_westwood.koのようなファイルがTCP congestion control algorithmを実装するカーネルモジュールです。次のように、特別な措置をしなくても、このリストにあるカーネルモジュールを使用できます。
echo "westwood" > /proc/sys/net/ipv4/tcp_congestion_control (OR) $ sysctl -w net.ipv4.tcp_congestion_control="westwood"
「sysctl net.ipv4.tcp_available_congestion_control」コマンドを使用すると、上記で追加されたアルゴリズムが、このリストにも追加されていることが分かります。
https://tools.ietf.org/html/draft-ietf-tcpm-initcwnd-00
http://www.cdnplanet.com/blog/tune-tcp-initcwnd-for-optimum-performance/
http://packetbomb.com/understanding-throughput-and-tcp-windows/
http://stackoverflow.com/questions/8893888/dropping-of-connections-with-tcp-tw-recycle
https://blogs.technet.microsoft.com/thenetworker/2008/04/20/of-tcp-sequence-numbers-and-paws/
http://unix.stackexchange.com/questions/210367/changing-the-tcp -rto-value-in-linux
http://vincent.bernat.im/en/blog/2014-tcp-time-wait-state-linux.html
http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html
https://www.frozentux.net/ipsysctl-tutorial/chunkyhtml/tcpvariables.html


NHN Cloud Meetup 編集部