NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2016.01.11
885
MySQL 5.7のJSON対応とNative Partition対応の新規機能について紹介したいと思います。
まず、MSR(Mulit-Source Replication)になることに非常に興奮しました。
DBAは実に重要な機能です。なぜなら、まずは下のサンプルを見てみよう。

共通DB、ゲームDB、ログDBで構成されたゲームがあるとします。ゲームDB、ログDBは複数でShardingされ、物理的に他の機器でサービスしています。ここで、ある指標を表示するため、すべてのDBで1度にクエリしてjoinをかける必要があるとしたら、どうなるでしょう。
以前はバッチ作業で特定の時点のデータをすべて流し、大きな機器に復元する必要がありました。
すごく時間がかかるし難しいですね。MySQLは特に復元に時間がかかります。
しかしMSRでは、ディスクが大きい機器1台をすべてのDBのslaveにすれば完了します。
他にもこのように様々な機能が強化されました。
次のものをサポートします。
注目すべきは、Native JSON data typeとIndexingでしょう。
通常、textカラムにjsonデータを入れてしまうと、後で検索するとき非常に苦労します。すべてのデータを読み終えてから再解析し、特定の項目を探してテーブルの別カラムに保存し、その後、当該カラムでインデックスを作成します。しかし、Native JSON data typeのカラムに入れておけば、もうそのような必要はありません。最初に入力したデータを構造化されたデータ形式で保存し、特定の項目をインデックスに追加しようとすると、テーブルのカラムにインデックスを作成するのと同じ位、速くインデックスにしてくれます。さらにインデックスがない場合でも検索が速くなります。
以下はOracleで実証した画面です。文法は気にしないでください。
JSON関連の関数で、JSONデータ内の特定の項目を抜き出す機能です。
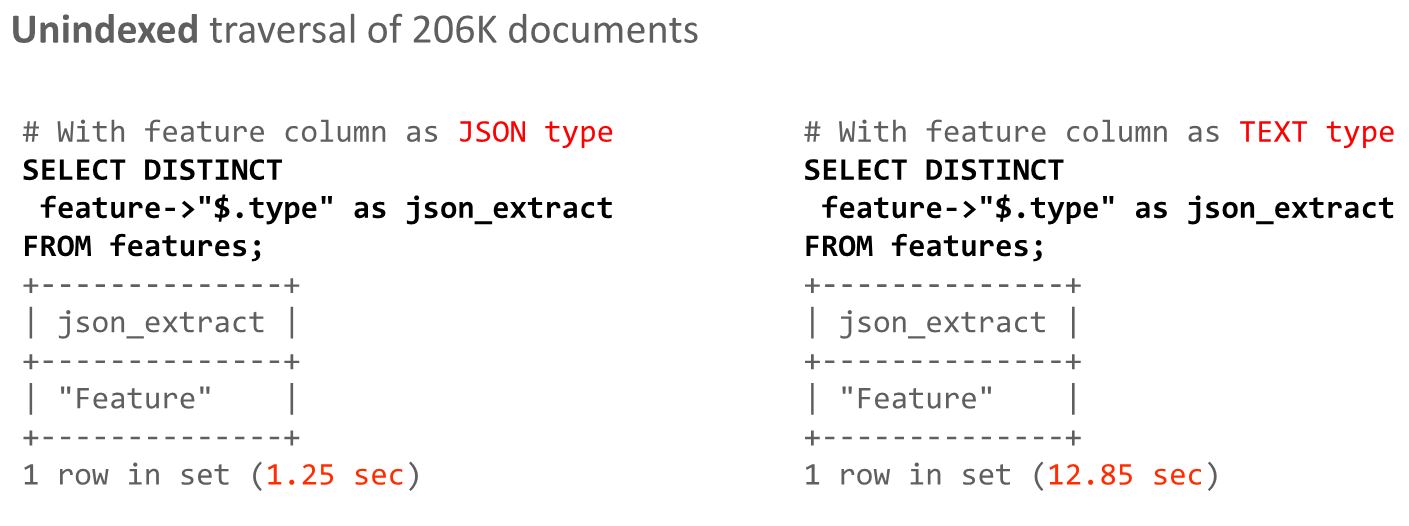 10倍速いですね。
10倍速いですね。
当該項目をカラムに抜き取ってインデックスにすると、select文にかかる時間は0.06 secまで減少します。
さらに、カラム作成からインデックス作成までに要する時間も1秒かかりません。
この関数は、マイグレーションや集計関数のような機能を提供します。
詳細は、[リンク]をご覧ください。ここで注意点が1つあります。character setは「utf8mb4」です。
セキュリティ機能が強化されました。しかし実際は少し不便に感じるかもしれません。
これが最も不便に感じる部分かもしれません。今後はSQL標準に合わない文法はより強く防止されます。
ONLY_FULL_GROUP_BY、STRICT_TRANS_TABLESが基本適用されます。
1)STRICT_TRANS_TABLES=>形式が合わない値をinsertするとき、以前はwarningされてもそのまま入力できましたが、今後はエラーになり入力できません。
2)ONLY_FULL_GROUP_BY==> group byしていないカラムをselectすることができません。
MSSQLのDMVのように、システムの状態が、より分かりやすくなりました。
これによってモニタリングなどが効率的に行えます。
mysqldumpというツールが登場しました。DBをdumpするとき、multi threadにバックアップを進行する速度が向上します。
1.複製はMSRなど様々な機能が追加されました。特にslaveが複数ある場合は、より便利に利用できます。
2 JSONはMysqlに保存しましょう。様々な関数とクエリ、強力な検索機能があります。
3.セキュリティの強化、SQLモードのデフォルト追加などは若干不便ですが、安全性が向上されました。
4. InnoDBのパーティション機能も使用できます。
5. Fusion IO使用時のパフォーマンスが非常に高くなりました。
6. SYSスキーマをはじめ、管理機能が向上しました。

NHN Cloud Meetup 編集部