NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2020.09.11
2,242
今年度のRedisカンファレンス(RedisConf 2020)はCOVID-19の影響によりオンラインで行われました。今回はその中で最も興味深かったキャッシュの性能向上について紹介したいと思います。なお、セッション映像はYouTubeでご確認いただけます。
Redisをキャッシュとして使用する場合、データを更新するためにほとんどのサービスではキーに対してExpire time(TTL)を設定しています。AWSはElastiCacheのキャッシング戦略文書において、データを最新の状態に維持しつつ複雑性を軽減するために、TTLを追加することを推奨しています。
しかし、大規模なトラフィック環境では、このTTL値が予期せぬ問題を発生させることがあります。
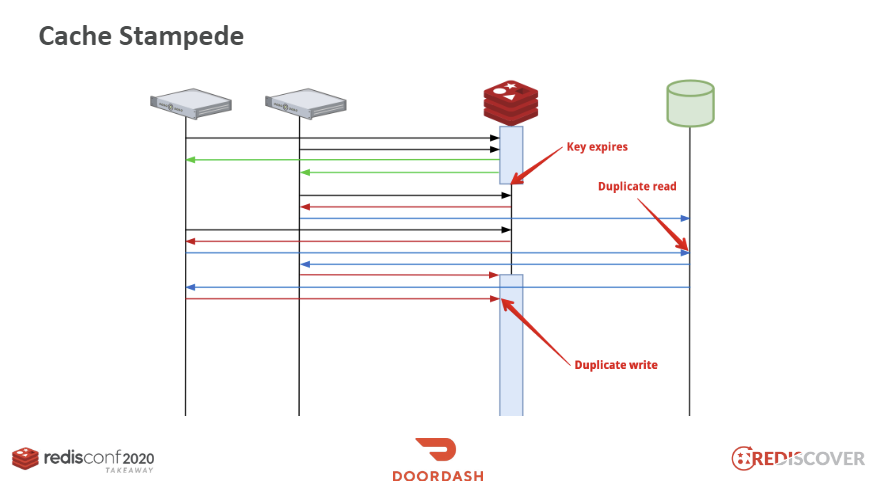 この構造ではRedisはキャッシュで、データベース(以下DB)の直前に分散されたサーバーからリクエストを受けています。キーの期限が切れた時点を考えてみましょう。read-thorugh構造でRedisのデータがない場合、サーバーは直接DBからデータを読み込み、Redisに保存します。キーの期限が切れた瞬間、多くのサーバーではこのキーを参照する時点が重なり、すべてのサーバーでDBからデータを照会するduplicate readと、その値を繰り返しRedisに書き込むduplicate writeが発生します。
この構造ではRedisはキャッシュで、データベース(以下DB)の直前に分散されたサーバーからリクエストを受けています。キーの期限が切れた時点を考えてみましょう。read-thorugh構造でRedisのデータがない場合、サーバーは直接DBからデータを読み込み、Redisに保存します。キーの期限が切れた瞬間、多くのサーバーではこのキーを参照する時点が重なり、すべてのサーバーでDBからデータを照会するduplicate readと、その値を繰り返しRedisに書き込むduplicate writeが発生します。
 この現象を解決するには、PER(Probablistic Early Recomputation、確率論的早期再計算)アルゴリズムを導入するという方法があります。このアルゴリズムは、キーのTTLが実際に切れる前に、一定の確率でキャッシュを更新します。キーが完全に期限切れになる前に、DBでデータをあらかじめ読み込んでおくことで、キャッシュ・スタンピード(Cache Stampede)現象を防ぐことができます。
この現象を解決するには、PER(Probablistic Early Recomputation、確率論的早期再計算)アルゴリズムを導入するという方法があります。このアルゴリズムは、キーのTTLが実際に切れる前に、一定の確率でキャッシュを更新します。キーが完全に期限切れになる前に、DBでデータをあらかじめ読み込んでおくことで、キャッシュ・スタンピード(Cache Stampede)現象を防ぐことができます。
def fetch_aot(key, expiry_gap_ms):
ttl_ms = redis.pttl(key) # pttlはmillisecond単位
if ttl_ms - (random() * expiry_gap_ms) > 0:
return redis.get(key)
return None
# Usage
fetch_aot('foo', 2000)
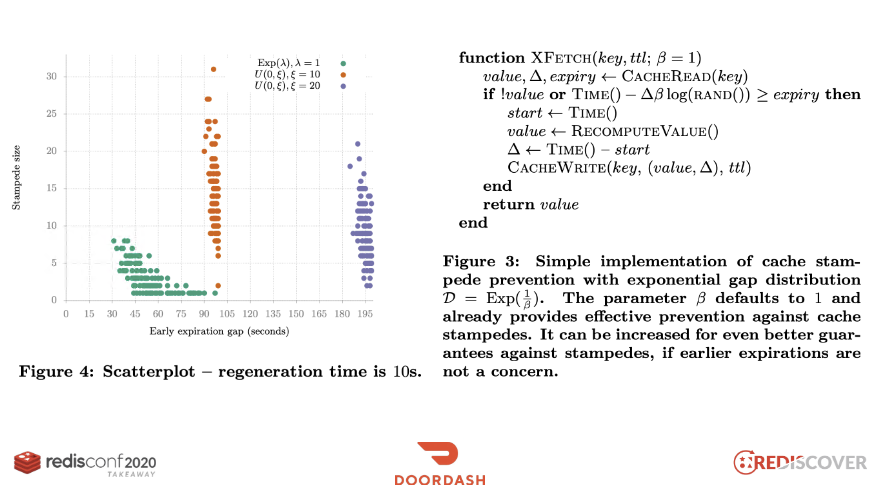
この方式はもともとVLDBという国際学術大会で発表された方法で、インターネットに関連する論文が公開されています。なぜこの確率分布が使用されるのか、またbeta値はどのように決めるべきかなどの内容も興味深いので、興味のある方は論文を読んでみてください。
We took inspiration from frontend world (debounce) and exploited promises(deferred)
また、キャッシュ・スタンピードの問題を解決するため、フロントエンド-ワールドでデバウンシングするというアイデアも採用できます。

この考えを導入すると、アプリケーションで特定のキーで失敗してもすぐにDBへ問合せを行いません。キーIDに対してデバウンサー(debouncer)を生成し、最初のリーダー(reader)がこの関数を返すまで、他のリーダーは待機します。このデバウンサーのコードは以下のとおりで、シミュレーターリンクでどのように動作するか確認できます。
const debouncer = new Debouncer();
async function menuItemLoader(key) {
//Read from Redis/DB
}
const menu = await debouncer.debounce(
'menu-${id}', menuItemLoader
);
class Debouncer {
construnctor() {
this.pendingBoard = {};
}
async debounce(id, callback) {
if(this.pendingBoard(id) !== undefined) {
return await this.pendingBorad(id);
}
this.pendingBoard(id) = callback(id);
try {
return await this.pendingBoard(id);
} finally {
delete this.pendingBoard(id);
}
}
}
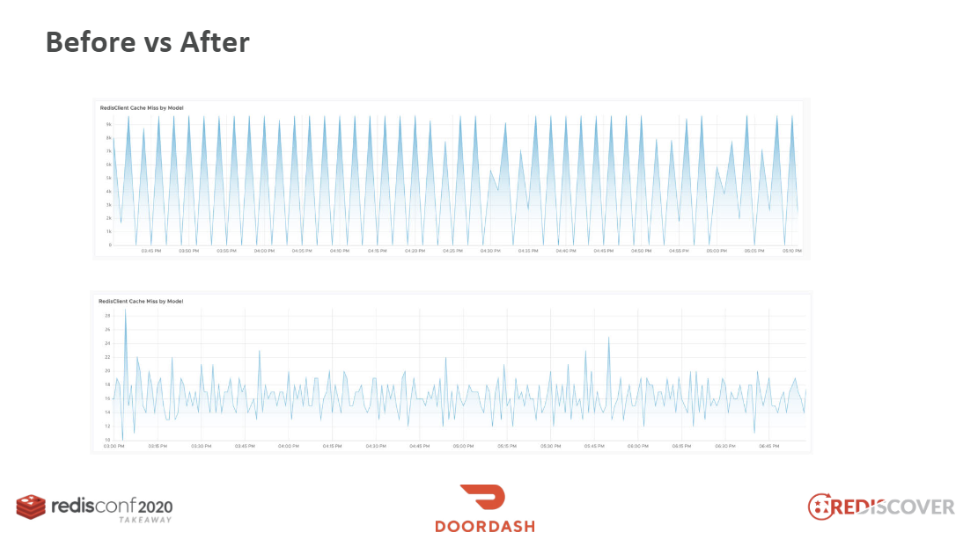
キャッシュ・スタンピード現象が発生した際のKey Missグラフは、上図の上方グラフのようにとがってギザギザしています。その反面、下方グラフでは、トラフィックが非常に減少したことがわかります。無駄なSETを減らすと、全体のラウンドトリップタイム(round trip time)が減少され、レイテンシ(latency)も減少します。実際にLINEでパフォーマンステストをした際に、このアルゴリズムを導入した場合は、約3倍の応答時間の改善が見られたそうです。
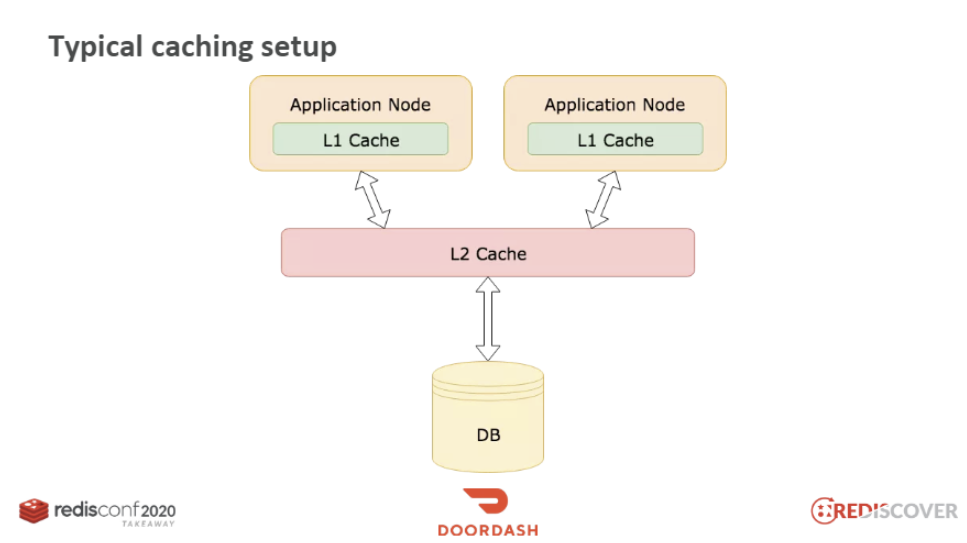
トラフィックが高いサービスでは、ほとんどこのようにキャッシュを構成しています。L1はアプリケーションキャッシュ(ex. Ehcache)、L2はRedisと考えることができます。先述のようにRedisとDB間のスタンピードの問題は、L1とL2間でも繰り返されることがあります。
Under high traffic load similar cache stampede/miss-storm can be observed between L1&L2 cache (and so on)
1つのキーへのアクセスが多すぎる場合にも問題が発生し、この現象もキャッシュの性能を低下させることがあります。
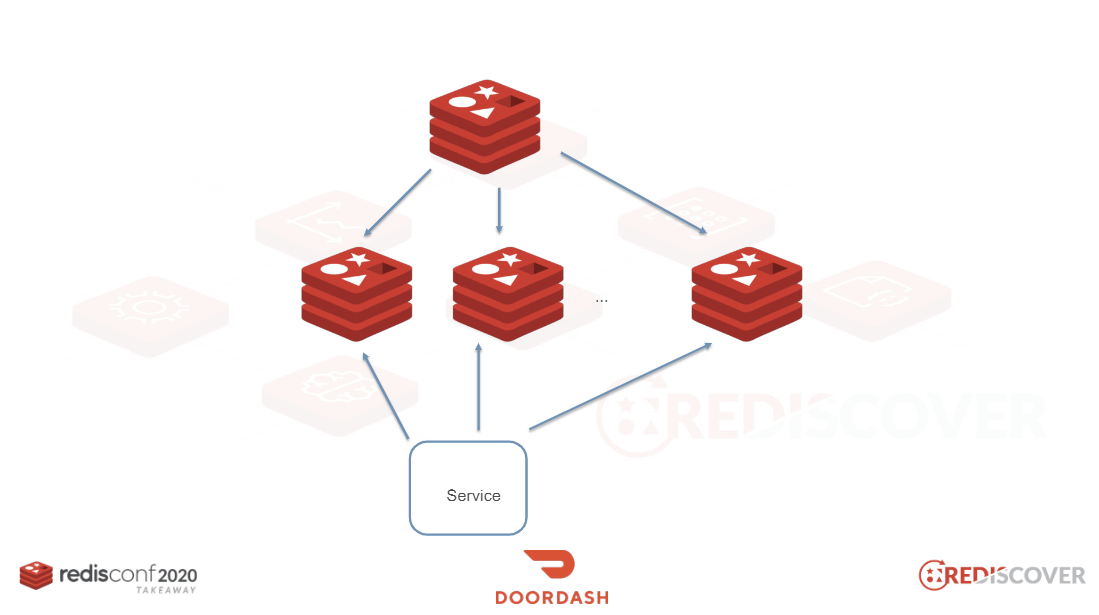 ホットキー(Hot Key)の問題が発生した際に最も簡単に考えられる代案は、読み込みの分散です。1つのマスターに複数のスレーブを追加し、アプリケーションでは複数台のサーバーからデータを読み込むといった方法です。しかし、このような構成では、障害が発生してフェイルオーバーになると状況が複雑になります。思わぬ障害やボトルネックが発生する可能性があります。
ホットキー(Hot Key)の問題が発生した際に最も簡単に考えられる代案は、読み込みの分散です。1つのマスターに複数のスレーブを追加し、アプリケーションでは複数台のサーバーからデータを読み込むといった方法です。しかし、このような構成では、障害が発生してフェイルオーバーになると状況が複雑になります。思わぬ障害やボトルネックが発生する可能性があります。
 このセッションでは、キーの複製を作成する方法を提案しています。
このセッションでは、キーの複製を作成する方法を提案しています。
def write_keys(key, copies):
return ["{{copy{}}}-{}".format(i,key) for i in range(copies)]
def read_key(key, copies):
r = randrange(0, copies)
return "{{copy{}}}-{}".format(r, key)
ホットキーを保存するときは、前にプレフィックス(prefix)をつけて複数のキーを作成します。キーを読み取るときは、そのプレフィックスを使用してランダムにアクセスするロジックを追加します。
RedisでマシンラーニングモデルやHTTPページなどを扱ったり、メッセージキューなどに使用してサイズの大きなデータを保存する際に、キャッシュの性能が低下する可能性があります。このときは圧縮が考えられます。圧縮を行う際には、次の点を考慮しましょう。
1つ目は、適切な圧縮比(Compression Ratio)です。高い圧縮率が重要なのではなく、適切な圧縮率を見つけなければなりません。なぜなら、圧縮をする際のCPUのパフォーマンスを考慮する必要があるためです。安定性ももちろん必須です。
また、複数の圧縮プログラムをベンチマークツールで確認し、適切なプログラムを探す過程も必要となります。
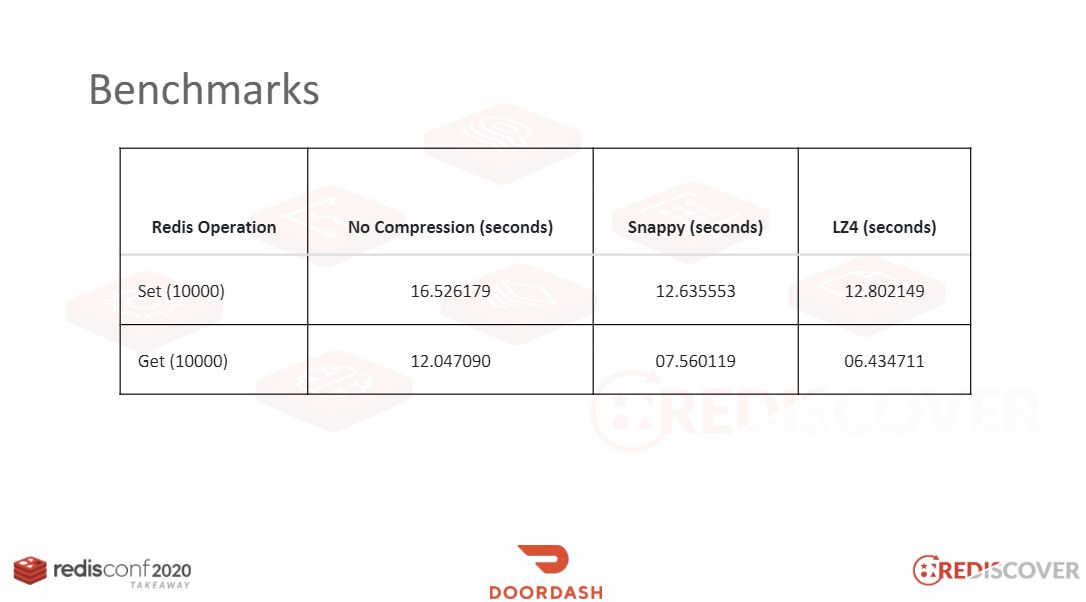 普段からサイズが大きいデータをそのままRedisに保存していれば、圧縮のみ実行しても次のように2倍近く性能を向上させることができます。
普段からサイズが大きいデータをそのままRedisに保存していれば、圧縮のみ実行しても次のように2倍近く性能を向上させることができます。
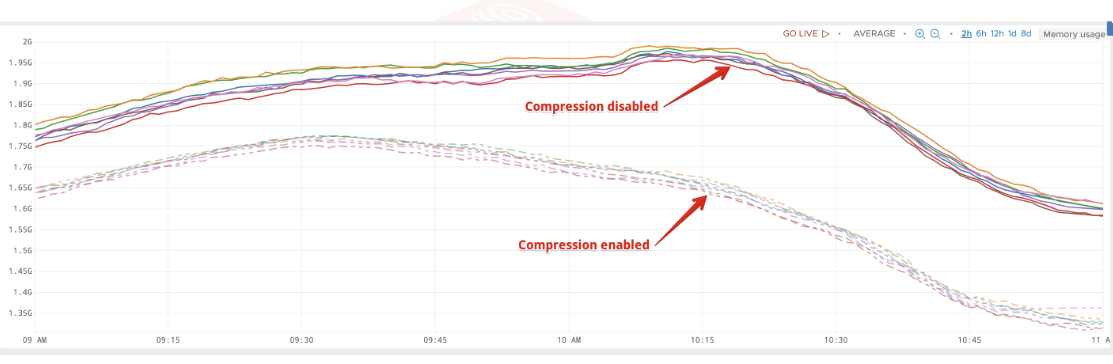
最後にNHNで運営しているあるサービスでキャッシュ・スタンピード現象が発生した事例を紹介したいと思います。このサービスでは、Redisにデータを保存する際に、TTL値の基本値を300秒で保存していました。これは一般的な状況では何の問題もありませんが、トラフィックが過度に集中する状況ではキャッシュサーバーに多大な負荷を発生させることが判明しました。この問題を分析する過程において、以下のログを確認することができました。


DBからデータを読み込んだ後、RedisにSETする過程で非常に長い時間がかかることがわかりました。また、このようなプロセスは、特定の時間帯に複数発見されました。これは明らかにRedisの性能を低下させることが予想されます。


NHN Cloud Meetup 編集部