NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2015.12.21
45,691
ネットワークのパフォーマンスを決定付ける最も重要な要素は、最終的にはアプリケーションにあるでしょう。ただ、ワークロードの特性によっては、デフォルト設定されたTCPカーネルパラメータが制約となり、パフォーマンスを発揮できないときもありますね。
非常にたくさんのカーネルパラメータがありますが、本文では、ネットワーク帯域幅(bandwidth)のカーネルパラメータ、ネットワーク容量(capacity)のカーネルパラメータを主に扱います。
Linuxはsysctlコマンドで簡単にカーネルパラメータを実行時に変更できます。
次のようなコマンドを使用すると、現在のカーネルパラメータ設定値の全体を閲覧できます。
$ sysctl -a
ここで取り上げるネットワークは、特にTCPのcapacityとbandwidthなどを調整(tuning)できるカーネルパラメータのごく一部を紹介します。
通常、TCPと関連カーネルパラメータは、net.core、net.ipv4、net.ipv6などの接頭辞を付けています。
また、次のようなコマンドで、現在の設定値を変更できます。
例えば、net.core.wmem_maxという設定値を16777216に変更するには、次のように入力します。
$ sysctl -w net.core.wmem_max="16777216"
システム起動時に設定されるようにするには、/etc/sysctl.confファイルに対応する設定値を記入します。
TCPの帯域幅を理解するには、まずBDP(Bandwidth Delay Product)について理解する必要があります。
100Mbpsの帯域幅を持つネットワークで、2つのhost A、B間のRTT(Round-trip time)が2秒であるネットワークパスがあると仮定します。
AからBまでデータが連続送信されているとき、Aから出発して、まだBに到着していないデータ量(bits in flight)はどれ位あるでしょうか?
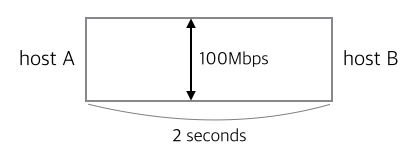
帯域幅を幅で、遅延時間RTTを長さで考えると、2つの積がネットワークパス上のフローティングデータ量の最大値を表します。
つまり、帯域幅と遅延時間の積、すなわちBDPは、ネットワークパスに転送されているデータ(パケット)の量を表します。
この例では、BDPは、100Mb/s * 2s = 200Mb / 8 = 25MB程度です。
他の例を挙げてみよう。サーバーとLTEネットワーク(40Mbps、40ms RTT)に接続された端末があると仮定します。
このときBDPは、(40(10^6))bit/s * (40(10^-3))s =1600(10^3)bit = 1.6Mb / 8 = 0.2MB程度になります。
BDPの式を利用すると、次のような式を導き出せます。
Bandwidth = BDP / RTT
ですが実際のインターネットでは、BDPは非常に大きいです。
これは物理的なネットワーク環境が以前と比べ飛躍的に向上しているためですが、インターネットでは、Bandwidth = (receiver window size) / RTTの関係も成立します。
整理すると、インターネットの場合、帯域幅を高めるには、RTTを下げるか、receiver window sizeを増加させるとよいでしょう。
しかし、RTTはpeer間の物理的な距離に依存しているため、下げることは難しいです。
よって、帯域幅を増やすには、receiver window sizeを増加させる必要があります。
では、receiver window sizeを増やすにはどうすればよいでしょうか?
基本的にTCP接続を結ぶとき、SYNパケットはreceiver window sizeを告知(advertising)するようになっています。
この値の範囲は0〜65,535まで、つまり64KBまで指定できます。
インターネットの黎明期ならいざ知らず、今の世界では64KBはかなり小さなデータ量です。
RFC 1323では、TCP window scalingというオプションを定義しています。
TCPヘッダのオプションフィールドにwindow scaleというフィールドを定義して、advertiseできるreceiver window sizeを増加させることができます。
この値は、0〜14まで指定できます。この値をnとすれば、2^nの値をwindow scaling factorと呼びます。
TCP window scalingを設定すると、実際のreceiver window sizeは、既存のwindow sizeの値とwindow scaling factorの積で求めることができます。
例えば、window sizeの値が8,192で、window scale値が8なら、実際のreceiver window sizeは、8,192 * (2^8) = 2,097,152バイトになります。
ちなみに、TCP window scalingを使用する場合、最大receiver window sizeは、65,535 * (2^14) = 1,073,725,440バイト(1GB)です。
TCP window scalingを有効にするには、カーネルパラメータ「net.ipv4.tcp_window_scaling」の値を「1」に設定します。
次のようなコマンドで有効にできます。
$ sysctl -w net.ipv4.tcp_window_scaling="1"
ちなみに、正しく動作させるには、通信する2つのhostの両方でTCP window scalingオプションを有効にしておく必要があります。
一般的に、クライアントOS(Windows、MAC OS X、iOS、Android)は、このオプションが有効になっています。
TCP window scalingを使ってreceiver window sizeの限界値を増加したとしても、実際のカーネルに設定されたソケットのバッファサイズより大きくなることはないでしょう。
結局のところ、receiver window sizeを増加させるには、ソケットのバッファサイズを増やす必要があります。
関連するカーネルパラメータは次のとおりです。
- net.core.rmem_default - net.core.wmem_default - net.core.rmem_max - net.core.wmem_max - net.ipv4.tcp_rmem - net.ipv4.tcp_wmem
rmemはreceive(read)bufferの大きさ、wmemはsend(write)bufferのサイズを表します。
指定された値の単位はバイト(bytes)です。
まずnet.coreプレフィックスが付いたカーネルパラメータから見てみましょう。
これは、TCPを含むすべての種類のソケットに基本設定されているバッファのサイズを表します。
サフィックスdefaultは、そのデフォルト値で、maxはソケットが保有できる最大サイズを表します。
net.ipv4プレフィックスが付いたカーネルパラメータは、TCPソケットの部分を設定します。
ちなみに、この設定値はipv6でも適用されますが、それはLinuxで一部のipv4カーネルパラメータがipv6まで適用されるためです。
(ipv6にも適用されるカーネルパラメータ:net.ipv4.ip_, net.ipv4.ip_local_portrange, net.ipv4.tcp, net.ipv4.icmp_*)
各カーネルパラメータは、min / default / max 3つの整数値に設定できます。
minは、TCP memory pressure状態のときにソケットに割り当てられるバッファのサイズを表し、maxはTCPソケットが保有できる最大サイズを表します。
TCP memory pressure状態については、もう少し後で紹介します。
中間値は、defaultにnet.coreで設定されたデフォルト値をTCPソケットに限定して上書きします。
特にデフォルト値は、TCP receive windowサイズを決定する際に最も重要なことに参照される値です。
このカーネルパラメータのデフォルト値は、Linuxカーネルによって自動設定(auto-tuned)されますが、通常は128KB程度に設定されています。
メモリ量が比較的少なく、大規模/大容量パケット処理を行わないデスクトップにおいては適切な設定です。
サーバーの場合は、一般的なメモリ量で適切にサイズを増やしても良いでしょう。(ネットワークの帯域幅-メモリ使用量のtrade-off)
TCP receive window sizeを増加させるには、上から並べたカーネルパラメータを適宜設定する必要があります。
どのようなワークロードでも適用可能な最適なカーネルパラメータは存在しません。
ただしこの場合、trade-offの関係がメモリ使用量しかないので、下記のような設定値を提案します。
(かなり保守的に上方修正された設定値です。)
$ sysctl -w net.core.rmem_default="253952" $ sysctl -w net.core.wmem_default="253952" $ sysctl -w net.core.rmem_max="16777216" $ sysctl -w net.core.wmem_max="16777216" $ sysctl -w net.ipv4.tcp_rmem="253952 253952 16777216" $ sysctl -w net.ipv4.tcp_wmem="253952 253952 16777216"
このほかに「net.ipv4.tcp_mem」というカーネルパラメータがあります。
これはカーネルでTCP用に使用できるメモリサイズを指定します。
上で紹介したパラメータは、個別のTCPソケットに指定される値で、この値はTCPソケット全体の値です。
この設定値は、上で紹介したカーネルパラメータと同様に、min / pressure / maxの値を指定できます。
このうち、pressureはnet.ipv4.tcp_rmem、net.ipv4.tcp_wmemで少し言及したmemory pressureのthreshold値です。
つまり、TCPソケット全体で使用されるメモリがこの値を超えると、TCP memory pressureの状態になり、以降ソケットは指定されたmin値のメモリバッファのサイズを持つようになるのです。
次のようなコマンドで、現在のカーネルパラメータ設定値を確認できます。
$ sysctl net.ipv4.tcp_mem net.ipv4.tcp_mem = 185688 247584 371376
上の値は、起動時にシステムのメモリに合わせて自動設定(auto-tuned)されます。
注意すべき点は、なるべくこのカーネルパラメータの設定値を変更しないということです。
なぜなら、すでにカーネルによってシステムメモリに最適化された値が設定されているからです。
Google検索などでヒットするカーネルパラメータの設定に関連した文書を見ると、この値を大幅に引き上げるようにガイドしているものもありますが、一部の文書では次のようにガイドしています。
$ sysctl -w net.ipv4.tcp_mem="8388608 8388608 8388608"
この設定値が、なぜ当てにならない数値かと言えば、その単位がバイト(byte)ではなく、ページ(page)であるからです。
Linuxでは、基本的に1ページは4,096バイトです。
つまり、上記の設定値通りなら8,388,608は、32ギガバイトを意味します。(あまりにも大きいですね)
では、receiverが発表(advertising)したreceive window sizeだけ、senderはデータをネットワークにパケット送信できるでしょうか?
結論から言えば、できません。
ネットワークは、ネットワークに接続されたすべてのノード間で共有される共有リソースです。個々のノードが突出して使用してしまうと、ネットワーク全体が麻痺する恐れがあります。
そのため、各ノードは適切なcongestion avoidance algorithmを用いて送信するデータ量を自主的に調整しています。
このcongestion avoidance algorithmはreceiverと関係なく(receiver window sizeなどpeerが知らせる情報とは関係なく)、独自にネットワークに送信するデータ量を設定します。
Linuxではreno、vegas、new reno、bic、cubicなどのcongestion avoidance algorithmが使用できますが、最近の一般的なLinuxディストリビューションでは、cubicが基本設定されています。
congestion avoidance algorithmは、いくつかのパラメータを参照(RTTが最も重要なパラメータとなるでしょう)して、congestion windowサイズを設定します。そして、このサイズが一度に送信できるデータ量の最大値になります。congestion windowサイズは、アプリケーションやカーネルパラメータで設定できる値はありません。
Linuxでは、ssなどのユーティリティを用いて、各ソケットで現在のcongestion windowサイズを確認できます。
$ ss -n -i
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 0 0 10.77.57.57:33000 10.77.57.57:47142
cubic wscale:7,7 rto:208 rtt:5.236/10.107 ato:40 mss:65483 cwnd:10 send 1000.5Mbps rcv_rtt:4 rcv_space:43690
このソケットは、congestion avoidance algorithmにcubicを使用して、現在のcongestion window sizeが10であることが分かります。
つまり、一度に送信できるパケット数は10個で、約15KB程度のデータを一度に送信できます。
このcongestion window sizeは、TCPの混雑制御戦略に基づいたslow startの方法で、最初の接続時に定められた「initial congestion window size(CWND)」からある程度まで継続的に増加することになります。
通信が継続的に進行するにつれて、receiverからACKパケットを受信すると、congestion window sizeを現在のサイズの2倍ずつ増加します。
(そのうちパケットが流出するとcongestion window sizeを減少させます。これは、congestion avoidance algorithmによって、どの程度軽減するかが異なります。)
ところが、このような特性のため、RTTが比較的高いモバイル環境では脆弱性があります。
例えば、receive window sizeが64KBのreceiverがあるとしましょう。senderのinitial congestion windowが1であれば、congestion window sizeが64KBに到達するには、peerから6回のACKが必要です。
RTTが500msであれば、3秒後にようやくreceive window sizeの大きさにcongestion window sizeが増加します。
このような理由から、Googleは2010年頃にTCP initial congestion window sizeを10に上方修正(一般的には1もしくは2に設定)しようという意見を出したりもしました。
しかし、繰り返しになりますが、すべてのワークロードの条件を満足させる設定値はありません。
ネットワーク上のすべてのpeerがinitial congestion window sizeを10に増加設定して、常にこのパケット数より多くの通信を頻繁に行うようになれば、ネットワーク全体が混雑した状況になるでしょう。
また、一度に送受信するパケットサイズが相対的に小さければ、initial congestion window sizeを調整しても大きな利益はありません。
initial congestion window sizeを変更するには、カーネルパラメータではなく、ip routeコマンドを使用できます。
まず、現在のルーティング情報を確認するには、以下のようなコマンドを使用します。
$ ip route show 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100 metric 1 169.254.0.0/16 dev eth0 scope link metric 1000 default via 192.168.1.1 dev eth0 proto static
ここではdefaultルーティングの設定を変更できます。上の設定値をもとに、次のように入力して、initial congestion window sizeを変更します。
$ ip route change default via 192.168.1.1 dev eth0 proto static initcwnd 10
次のようなコマンドで、適用されたか確認できます。
$ ip route show 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100 metric 1 169.254.0.0/16 dev eth0 scope link metric 1000 default via 192.168.1.1 dev eth0 proto static initcwnd 10
参考までに、特定のカーネルバージョン(2.6.18)では、ethernet設定からTSOを有効にすると、この数値が無視されるバグがあります。
(比較的古いカーネルと最近のディストリビューションでは関係ありませんが、Redhat / CentOS 5のバージョンはこのカーネルを使用します。)
また、slow startに関連するLinuxのカーネルパラメータは「net.ipv4.tcp_slow_start_after_idle」です。
このパラメータは、0もしくは1に設定できます。
1に設定されていると、congestion window sizeを増加させたソケットであっても、特定時間内にidle(通信がない)状態に持続されると、再びslow startを使用してinitial congestion window sizeからcongestion window sizeを増加させる必要があります。
反対に0に設定されていれば、一定時間通信がなくてもcongestion window sizeが維持されます。

NHN Cloud Meetup 編集部