NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2015.11.30
564

Deview 2014の主要な議題を整理してみました。
Deview 2014に参加する機会があり、そこで印象深かった内容をみなさんにも共有したいと思います。
まず、CoreOSという分散環境指向OSについて紹介します。
以下は、Deview 2014イベントの発表資料です。
http://www.slideshare.net/deview/2c4clustered-computing-with-coreos-fleet-and-etcd
CoreOSは、2013年10月に初期バージョンをリリースした新生Linuxディストリビューションです。
Deview 2014では、このプロジェクトのミッションを「インターネットを安全に守る(secure the internet)」と紹介しました。CoreOSの開発者は、このミッションの第一歩が、OSの自動アップデートであると考えたようです。
OSをアップデートするということは、内部システムの根幹であるカーネルとデバイスドライバを更新することです。そのため、CoreOSはOSイメージを中央リポジトリに保持しています。そして、定期的にバージョンをpollingして確認することになりますが、これにはGoogleの「Omahaプロトコル」を使用します。このプロトコルは、xml基盤の文書をHTTP通信で送受信します。
カーネルイメージを交換する作業が必要で、一般的にサービスが動作するライブ環境では進行しにくいです。CoreOSは、この問題を解決するため、次のようなトリックを使用しています。
読み取り専用のルートファイルシステムを2つ作成します。1つはactive、もう1つをpassiveルートパーティションと見做します。現在起動時に使用したルートパーティションをactiveとすると、アップデートの間、passiveパーティションのOSイメージをすり替えます。そして、GPTを変更して、passiveパーティションをactiveパーティションに変更し、再起動してOSアップデートが完了します。
この動作ではOSの部分的なアップデートはありません。つまり、変更された部分だけを受信するdeltaアップデートや、複数段階のアップデートには対応していません。このため、CoreOSはOSイメージを多く見積もって100MBで作成しています。OSイメージだけでアップデートが行われる格好ですね。特異点は、aptやyumのようなパッケージマネージャを別に置いていないところです。これは、Linuxコンテナに関連する部分なので後述します。
このとき、OSのアップデートを完了させるには再起動が必要です。この問題を克服するために、fleetという独自のクラスタレベルのinitシステムを保持しています。一般的なUnixシステムのinitプロセスが、すべてのプロセスの親プロセスで動作するように、fleetはCoreOSクラスタに動作するアプリケーションの親の役割を持ちます。
CoreOSは、fleetを使ってクラスタに動作するアプリケーションをスケジューリングし、1つのシステムのOSアップデートの間(つまり、downtime)、全体のサービスがダウンしないように処理します。
ホームページにアクセスすると、上のようなモットーを確認できます。CoreOSは様々な独自コンポーネントを提供しています。まず簡単に紹介すると、次のとおりです。
個々のシステム(ノード)を図で表してみましょう。
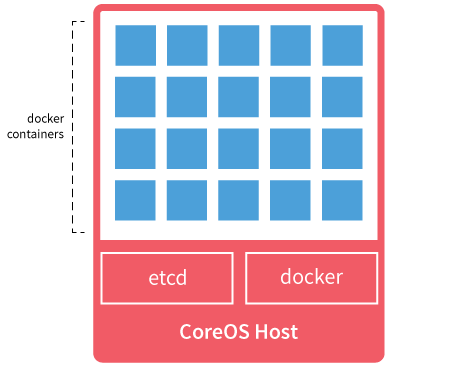 このような多数のノードで構成されたクラスタは、次のように表せます。
このような多数のノードで構成されたクラスタは、次のように表せます。
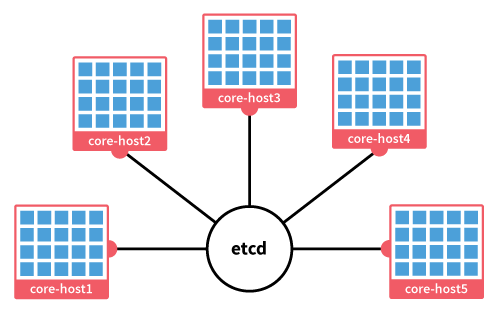
つまり、分散ストレージのetcdを中心に、個々のシステムのfleetが連結され、クラスタが構成されます。
fleetはdockerを利用して、アプリケーションを駆動します。
理解を深めるために、CoreOSを構成する技術を羅列してみましょう。
CoreOSはChrome OSを基本ベースに派生したLinuxディストリビューションです。
OSアップデートに使用されるOmahaプロトコルもここから取得されたと考えられます。
Dockerは、オープンソースのLinuxコンテナプラットフォームです。
コンテナは、簡単に「軽い仮想マシン」と考えるとよいでしょう。
下図は、一般的な仮想マシンとコンテナとの違いを表しています。
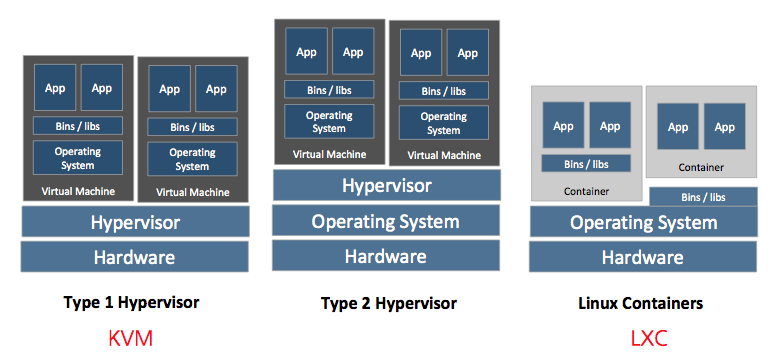 例えば、OpenStackで主に使用されるKVMやXenの場合は、上図では、Type 1 Hypervisorを使用するVMです。
例えば、OpenStackで主に使用されるKVMやXenの場合は、上図では、Type 1 Hypervisorを使用するVMです。
virtualboxやVMWare fusion、parallelsのようなソリューションは、Type 2 Hypervisor VMです。2つのタイプとも仮想アプライアンス別に、つまりguest VM別に、OSのカーネルが動作します。
lxcのようなコンテナはこれとは異なり、guestにOSカーネルが必要ありません。hostのOSを共有するからです。そのため、一般的なVMのリソース分割のような利点を持ちながら、個別のイメージサイズを減らすことができます。また、guest毎に別途OSを起動する必要がなく、一瞬のうちにguestを駆動できる利点があります。1つの階層を減らしてパフォーマンスを高めましたが、もちろん一般的なVMのみのリソース隔離(isolation)は行われません。
下記はkvmとlxc間の性能を簡単に表にしたものです。
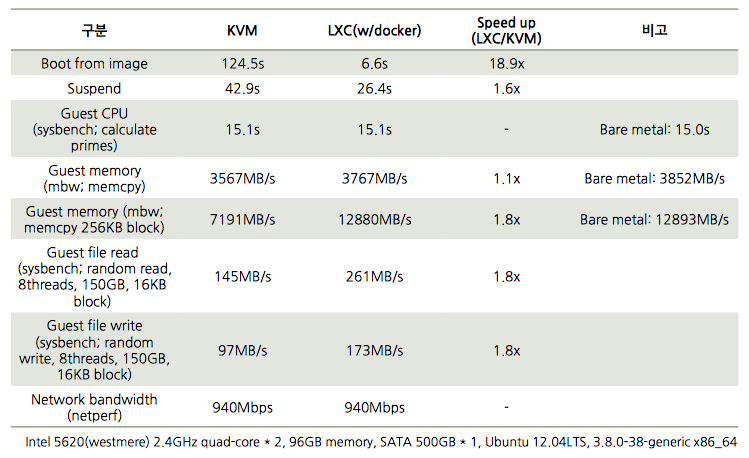 (出典:http://www.slideshare.net/BodenRussell/kvm-and-docker-lxc-benchmarking-with-openstack)
(出典:http://www.slideshare.net/BodenRussell/kvm-and-docker-lxc-benchmarking-with-openstack)
CoreOSでは、すべてのアプリケーションがDockerを用いて駆動されます。Dockerコンテナのイメージ自体が、実行されるアプリケーションであるため、CoreOSは別途パッケージマネージャを保有していません。
その代わりに、例えばWebサーバーのnginxをCoreOSで駆動する場合、ストア(privateストアor Docker publicストア)でnginx Dockerイメージをダウンロードします。そしてこれを駆動して実行します。この作業は、fleetを用いてクラスタスケールで拡張可能です。
systemdは、従来のinitの代替となるLinuxの新しいPID 1プロセスシステムです。すべてのプロセスを生成するあらゆるプロセスの親としての役割を持ちます。CentOS/RHEL(7以上)、Debian/Ubuntuといった大型のディストリビューションで代替されたり、代替計画が発表されています。
既存のinitとは異なるリソース分割を行うcgroupsと、一種のAPIでUDSやD-Busインタフェースも提供しています。また、プロセスのヘルスチェックが可能で、失敗したサービスは再起動する機能も備えています。
CoreOS fleetは、D-Busインタフェース(正確にはIPC)を用いて、systemdにDockerイメージの起動や停止を命令します。systemdでは個々のアプリケーションをunitと表現しますが、fleetはunitの状態も、このインターフェイスを用いて定期的に受信します。
fleetはクラスタレベルのinitシステムと言えます。CoreOSは個々のシステムレベルでは、プロセス管理のためにsystemdを使用しますが、クラスタレベルでは、fleetを使用します。
個々の機器にインストールされたfleetエージェントは、D-Busを通じてsystemdにアクセスし、現在のローカルシステムで駆動されているサービスを知ることができます。そして、systemdを用いて(再びDockerを用いて)アプリケーションを駆動できます。
fleetを利用したアプリケーションを駆動する過程は、次のとおりです。
さらに詳しい内容は、下記のリンクからご確認いただけます。
https://www.digitalocean.com/community/tutorials/how-to-create-and-run-a-service-on-a-coreos-cluster
unit(すなわちアプリケーションorサービス)をクラスタレベルで駆動するには、クラスタを構成する各ノードの情報や状態などを、中央集中的なストアで管理する必要があります。そして、その集中リポジトリは、単一障害点 / single point of failure(SPOF)となるので、優れた高可用性 / High Availability(HA)が要求されます。
fleetと類似するプラットフォームでは、Apache Mesos(http://mesos.apache.org)があります。Mesosでは、このリポジトリにZooKeeperを使用しています。CoreOSでは、次の章でお話するetcdを使用しています。
CoreOSはクラスタ情報管理のため、etcdという高可用性の集中リポジトリを使用しています。
一般的に、このような用途のストアにはZooKeeperが用いられますが、CoreOSではetcdという別途ソリューションを使用しています。
CoreOSはGo言語で作成されています。ZooKeeperはJavaという言語に依存しており、これ以外の言語では少し困った点があります。
最大の問題は、ZooKeeper自体がとても肥大だということです。このようなクラスタシステムにおいて、ZooKeeperはconfiguration管理やノードのfault detection用として主に使用されていますが、すべての機能を使用しない状況では、一定の機能のみを使用するクラスタのコア要素として、オーバースペックになる可能性があります。また、ZooKeeperのephemeral nodeを使ってfault detectionをしている状況においては、ZooKeeperの一時的な性能低下によってノードの状態をfalse negativeと判定してしまい、最終的にすべてのノードで障害が発生することもあります。ZooKeeperは、古くから非常に安定的に動作するオープンソースのソリューションや、CoreOSのような小さな機能を上手く集中させようとするプロジェクトでは、オーバースペックと判断されるようです。
またZooKeeperは、Paxosというコンセンサスアルゴリズム(consensus algorithm)を使用しています。分散環境で一定の性能を確保するには、分散環境を構成する各ノード間の相互意見の妥協点が必要ですが、これに対してPaxosというアルゴリズムを使用しています。このアルゴリズムは、80年代にLeslie Lamportという分散システムの対価によって考案されましたが、非常に理解しにくいアルゴリズムとして広く知られています。
現時点でZooKeeperのLOCは137kラインです。ZooKeeperはこのように巨大な規模を持ちますが、その基盤であるアルゴリズムは難しいわけです。ちなみに、ZooKeeper以外にも有名なGoogleの分散ロックシステムであるChubbyが、このPaxosを使用しています。
etcdはRaftというPaxos代替アルゴリズムを使用しています。Raftは2013年にスタンフォードのDiego Ongaroが考案したコンセンサスアルゴリズムで、Paxosと同じ機能を持つ上に、簡単に理解できるように作成されています。
etcdは17kのLOCを保有しています。(サードパーティまで含めると33k)
CoreOSはfleet、etcdなどの実装をすべてGo言語に統合しています。Go言語は、かの有名なKen Thompson、Rob Pikeが2007年にGoogleで作成した言語です。
コンパイル時型推論(compile-time type inference)、ビルトイン同時実行プリミティブ(ex. channel, light-weight thread;goroutine)などを提供する最新世代の言語です。
最近になって開発者たちから脚光を浴びています。Pythonのように簡単な文法で、すでにほとんどの機能がビルトインされた近代的な標準ライブラリは、Pythonよりもはるかに優れたパフォーマンス(コンパイル言語のため)、静的コンパイル(動的ライブラリのように配布する必要がなく、バイナリ1つだけ配布すればよい)などが、大きなスコアを受けたようです。
この言語の創始者であるRob Pikeは、ますます複雑になるC++開発者のためにこれを作成し、市場でPythonの開発者に大々的にアピールしています。
CoreOSはminimal OSを目指し、Go言語はminimal配布をその強みとしているので、相性が良いと思います。
Deview 2014では、実際にCoreOSを開発、進行する上で、障壁となるいくつかの問題とその克服方法を紹介しています。
これを解決するため、fleetがunitをスケジューリングするとき、各ノードの状態とunitの状態をすべて照会してからスケジューリングを進めるreconciler modelを使用しています。最終的にスケジューリングにブロッキングが生じて、効率は下がりますが、安定性は高まるようです。
CoreOSは、こうした点を補完するため、reconciler modelを適用するトリガーとしてwatchを使用する、といった最適化方法を考案しています。
つまり、そのバイナリの中にアプリケーションを実行するコードとgolang runtimeがすべて含まれています。そのため、他の言語で作成されたアプリケーションよりも、はるかに大きいサイズを持ちます。単にhelloworldだけを出力するアプリケーションであっても、10メガバイトに迫ります。
幸いなことに、Golangバージョンが上がるほど、コードが最適化され、容量が少なくなってきています。
CoreOSではこの受動的な方法で、Golangバージョンが上がり、バイナリサイズが減少されることを期待しています。
また積極的な方法として、1つのトリックを使っています。それは、バイナリに複数のコンポーネントをすべて入れる方法です。シンボリックリンクを使って複数のプログラムの名前でリンクを作成します。その上で、main関数においてargvについた引数のうち、最初の引数であるプログラム名に分岐して、該当の構成要素として動作させます。こうすると、golang runtimeに必要な重複的な容量を減らすことができます。
CoreOSは「cluster by default」というフレーズが印象的な、もう1つのクラウドソリューションです。基盤技術としてsystemdやDockerのような比較的最新の技術を上手く混ぜ合わせて構成しています。一時、VM技術によって完全に隅に追いやられたコンテナが、Dockerというリリーフ投手によって再び水面に浮上した点が注目に値します。クイック配布/駆動が大きな利点であるコンテナ技術がクラウド時代に脚光を浴び、VMと肩を並べられるかも観戦のポイントです。
また、これらのクラウドソリューションは、暗黙的にOpenStackの元に集結していますが、CoreOSもまた例外ではなく、OpenStackとどのように相乗効果を出せるかにも関心が集まるところです。

NHN Cloud Meetup 編集部