NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2024.03.29
834

こんにちは。 NHN CloudのクラウドAIチームのパク・ヒョンモクです。
異常検知(anomaly detection)という用語を一度は聞いたことがあるか、聞いたことがなくても、その意味を理解するのに苦労はないでしょう。 しかし、普段より深い内容が気になる方、または今少し好奇心が湧いた方のために、浅くでも私が知った知識を共有したいと思います。
始める前に、少し哲学的な(?)質問をさせていただきます。
正常とは何なのか、何を基準に異常を見分けるのか?
本当はここまで真面目な質問は必要ないのですが、私が言いたかったのは、異常(anomaly)というものを見つけるためには、まず何が異常なのかということを明確に定義する必要があるということです。 やはり明確な定義は難しいですが、一言で異常を定義するならば、異常は特異で珍しい出来事と言えます。 それって明確な定義なの? と思われるかもしれませんが、ここからのお話はすべて珍しいという概念から出発していることをこれからゆっくりとお伝えしていきます。
つまり、異常検知(anomaly detection)とは、私たち独自の基準を設けて、異常値、珍しい事象を検知することです。適切なモデルを通じてベースラインを作成し、異常を事前に検知して警告を発し、根本的な原因を解決して備えることが、異常検知の目的であると言えます。
誰かが私たちに事前に株式市場のボラティリティを認識し、警告してくれれば良いのではないでしょうか?
上記で私が異常(anomaly)とは特異な値と珍しい出来事と言いました。 では、これらはどのように定義することができるでしょうか。 学者はNovelty/Outlierという言葉を使い、下記のように定義しました。
定義だけ見ると、何か知っているようで知らないような気がします。しかし、異常検知ではこの2つの用語は明確に区別して使用しており、異常検知のサブカテゴリであるnovelty detectionとoutlier detectionも明確に区別されています。簡単な話を通して二つの用語の違いを見てみましょう。
宇宙のどこかに赤いリンゴとスイカだけが育つApple worldという場所があります。しかし、なぜかスイカはとっくの昔に姿を消し、その姿だけが住民の間で伝えられていました。 ある日、市場で買ってきたリンゴをバスケットから一つずつ取り出していたイサンは、突然手から異質な感覚を覚えます。何か滑らかで、片手ではつかめない、さっきまで取り出していたリンゴとは明らかに違う!スイカを取り出し、調べていたイサンイは、これが伝説のスイカであることに気づきます。 同じ時間、Apple worldの別の場所では、緑色のリンゴが発見されます。住民たちはこれがリンゴであることは大体わかっていましたが、今まで見たことのない緑色のリンゴだったので、戸惑いを隠せません。
まず、このような低レベルな話をしたことをお詫び(🍎)します。 理解を助けるために無理矢理話を作りましたが、NoveltyとOutlierの特徴がすべてこの話に詰まっています。すでにお気づきかと思いますが、この話でNoveltyは青リンゴ、Outlierはスイカです。Noveltyの最大の特徴は、見たことがないということです。 すべての条件を問わず、私たちが初めて見るデータであれば、それはNoveltyと定義されます。Outlierの特徴は違うということです。 すでに知っているかどうかが重要ではなく、今私たちが持っているデータバスケットと違うかどうかがOutlierを区別する方法です。
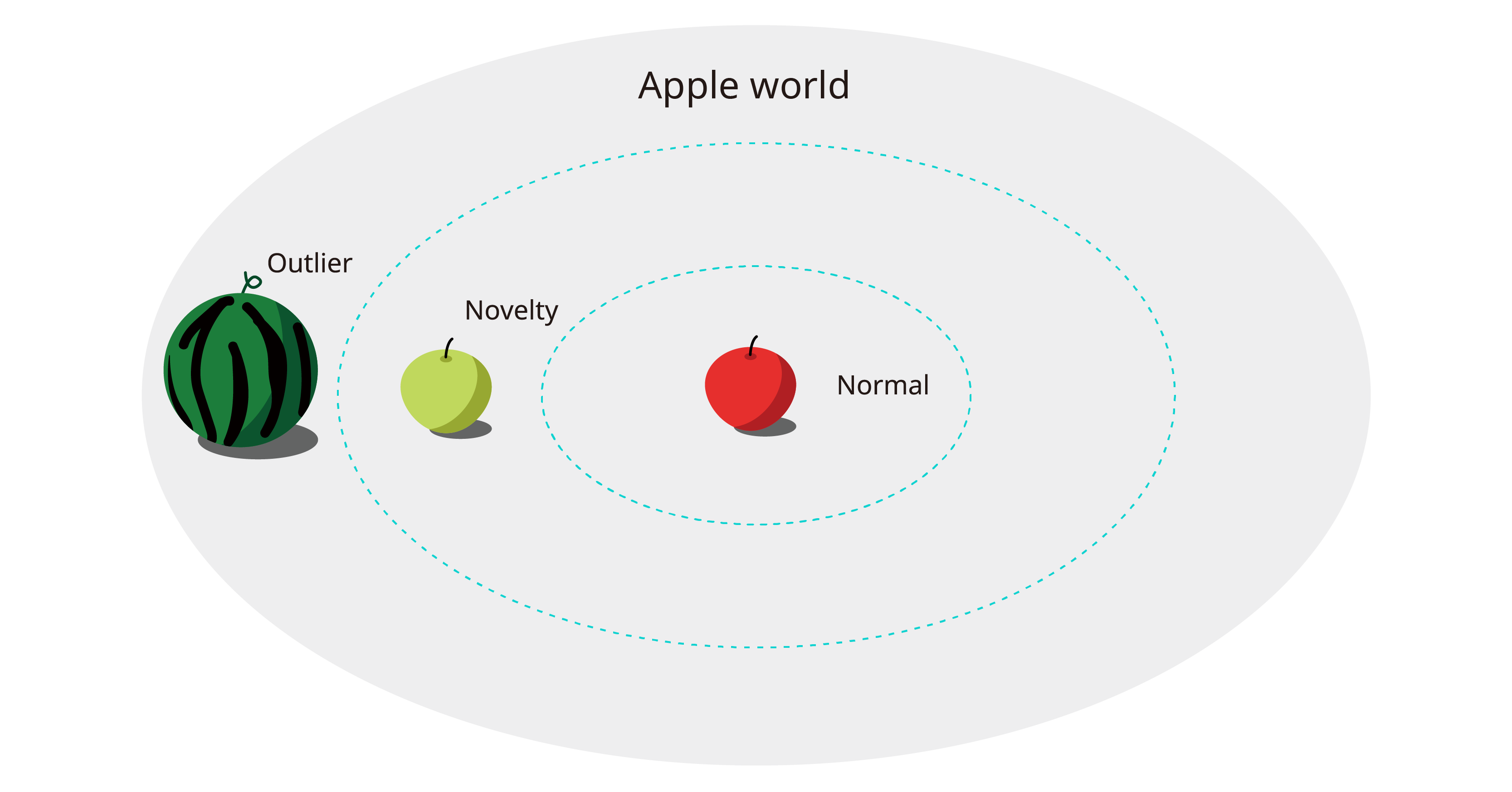
Q) Novelty=正常、Outlier=異常?
上の図だけ見ると、「Noveltyは少し変わったデータであって、異常なデータではないのではないか?Outlierを見つけ出せばいいのでは?」と思うかもしれません。どちらの質問も間違いではありませんが、厳密に言うと質問から間違っています。 一般的に知っている異常(abnormal)と異常検知における異常(anomaly)は似ていますが、意味が違います。
 異常(abnormal)は一般的な観点から望ましくない行為を指しますが、異常(anomaly)は行為よりもデータに対象を置き、従来と違うということに焦点を当てています。上記で、異常検知は特異な値、珍しい事象を事前に検知する技法と言いました。 したがって、異常検知は異常(abnormal)よりも異常(anomaly)を見つけることに目的を置きます。ただ、便宜上、異常(abnormal)、異常(anomaly)を同じ意味で使うことがあります。
異常(abnormal)は一般的な観点から望ましくない行為を指しますが、異常(anomaly)は行為よりもデータに対象を置き、従来と違うということに焦点を当てています。上記で、異常検知は特異な値、珍しい事象を事前に検知する技法と言いました。 したがって、異常検知は異常(abnormal)よりも異常(anomaly)を見つけることに目的を置きます。ただ、便宜上、異常(abnormal)、異常(anomaly)を同じ意味で使うことがあります。
これで二つのデータがどのような違いがあるのか明確に区別できるようになりました。 では、方法論の面ではどのような違いがあるのでしょうか。 二つの方法論を区別する基準は、学習データの特性と検知対象領域にあります。理解を助けるために、以下の表に定義、データ特性、異常検知で呼ぶ用語を基準に2つの技法をまとめました。 長く書きましたが、核心はどのようなデータを学習し、どこで異常データを探すかということです。
|
定義 |
学習データ特性 |
検知対象 |
異常検知 |
|
|
Novelty detection |
新しいデータが学習されたデータ分布に含まれるかどうかを判断します。 |
正常なデータのみで構成 |
新しい入力 |
Semi-supervised anomaly detection |
|
Outlier detection |
学習データ内でデータが最も多く集中している領域を見つけ出し、それ以外のデータを除去すること。 |
正常/異常データが全て存在 |
学習データ内で除去 |
Unsupervised anomaly detection |
上でNoveltyは見たことがないデータと言いました。 なので、novelty detectionの目標は文字通り見たことがないデータを見つけることです。 そして、見たことがないことは学習データによって決定されます。上のリンゴの問題で、モデルが赤いリンゴだけを学習した場合、モデルの立場からすると、緑のリンゴ、スイカの両方とも見たことがないデータ(novelty)になります。 逆にスイカと緑のリンゴだけを学習した場合、今度はむしろ赤いリンゴが見たことがないデータになります。 このように、学習データをどのように構成するかによってnoveltyの基準が変わる可能性があり、新しく入力されるデータだけを対象にテストを行います。
一方、outlier detectionの学習データは、正常/異常の両方のデータが存在します。モデルの目標は、与えられた学習データから最も多くのデータが集中している領域を見つけ出し、領域外のデータ(outlier)を除去することです。 したがって、別途のテストデータを必要としません。 このような特性のため、novelty/outlier detectionを異常検知ではsemi-supervised/unsupervised anomaly detectionと呼びます。
難しい!何がいいんだ、うまくいくものだけ使えばいいんじゃないのか?
単刀直入に言うと、データの関係でそうしたくてもできません。後述しますが、異常検知は正常/異常データの不均衡が非常に激しい分野です。さらに、何が正常/異常データなのか、明確に区別するのも難しいです。 今、私たちが確保したデータが全て正常だと思ってnovelty detectionを適用したのに、後で気づいたら異常データが混ざっていたとしたら…?😨
したがって、現在持っているデータに合わせて2つのうち適切な方法を選択することが、良い異常検知のための第一歩と言えます。ここでは、簡単な例だけを紹介し、2つの手法の説明は終わります。
下の図で、白い点が学習データであり、紫色の点が正常データ、黄色い点が異常データです。赤い線で表示された領域がモデルが見つけた学習データの分布であり、この時、新しいデータがその中に入ってきたら正常データと見なします。
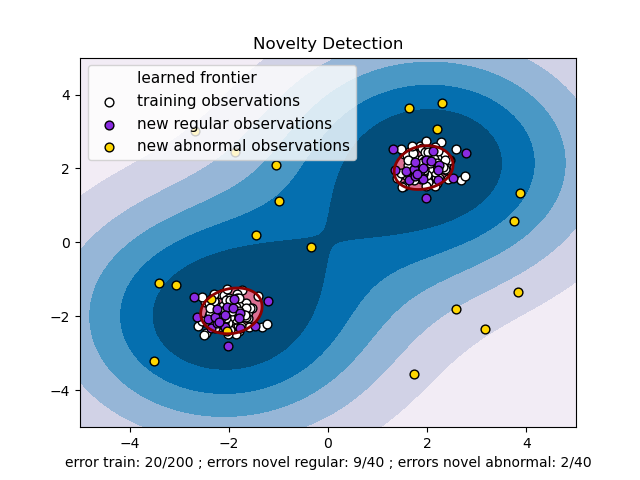
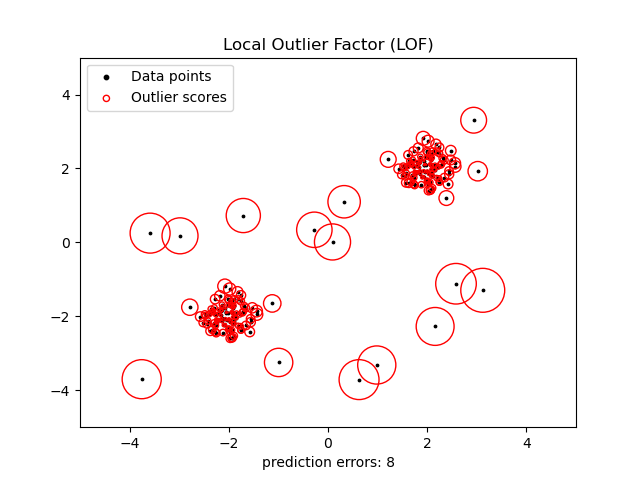
学習データをよく説明できる分布を見つけることはnovelty detectionと似ていますが、今回はすべてのデータをよく説明できるように強制しません。 下の図はLocal Outlier Factorという代表的なoutlier detectionモデルの例です。黒い点で表現されたデータのうち、密度が高い領域のデータは赤い丸で表現されたoutlier scoreが高くないことが確認できます。しかし、密度が低いデータはoutlier scoreが高くなっています。学習データ内でこのような集まりを見つけることがoutlier detectionの主な目的であると言えます。有名な群集化アルゴリズム(例えば、K-meansなど)がoutlier detectionによく使われます。
異常検出に使用されるデータは特に制限はなく、検出したい目標、対象によって様々なデータを使用できます。サーバーが正常に動作しているかどうかを検査するのであれば、CPU、メモリ、トラフィックなど、サーバーの動作プロセスで抽出できるすべてのデータを使用ができます。製造設備では、工程検査のために製品の外観画像を使用することもできます。このように、目的や分野によって様々な異常検知が適用される可能性があります。
何個のデータを同時に使用するかによっても区別します。 一つのデータだけを使用する場合は単変量(univariate)、複数のデータを同時に使用する場合は多変量(multivariate)といいます。 異常検知では、変数間の関連性も重要な要素として作用するため、単変量、多変量を区別することが非常に重要です。
また、CPU使用量のように連続的に発生する連続的な観測値を時系列データ(time-series)と呼び、以降は時系列データを中心に説明します。
時系列データにおける異常とは何を意味するのでしょうか?一般的に、時系列データは値そのもの(平均、最大値、最小値)も重要ですが、規則性も重要な要素として作用します。 また、時系列データの特性上、異常データが短期的または長期的に現れることもあります。このような特性によって、時系列の異常データを以下のように分類します。
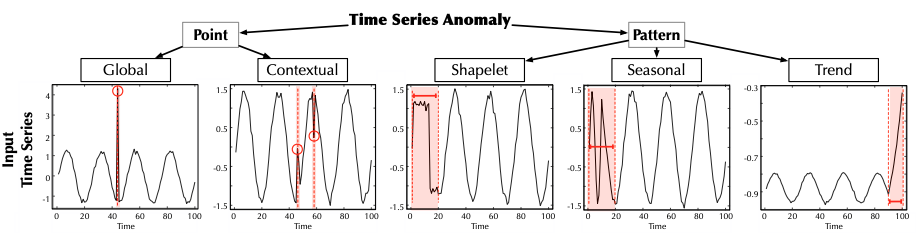
まず、異常データが現れる期間によって大きくPoint time-series anomalyとPattern time-series anomalyに分類します。
異常検知が難しい理由には様々な理由がありますが、根本的な理由は、ドメインに対する知識が不足していることです。基本的に、正常/異常データを区別するためには、何が正常なのかを把握する必要があります。 意図していない動作を異常と解釈すればいいのでは? と疑問を持つかもしれませんが、そう簡単ではありません。 一般的な状況では、異常データは非常に稀であり、明確でない場合が多いです。まるで元暁僧侶の骸骨水の物語のように、私たちは異常であることを全く感じずに過ぎてしまうこともあります。 したがって、ドメインに対する知識が十分でない場合、正常/異常データが混在する問題(anomaly contamination)が発生する可能性があります。
また、データが生成・測定されるプロセスを深く理解する必要があります。データ測定プロセスで発生するノイズ、損傷は必ず前処理のプロセスを経なければなりませんが、この時、十分なドメインの知識がなければ、後で多くの問題が発生する可能性があります。
上でも述べたように、一般的に異常データは非常に稀であり、明確ではありません。 非常に少量の異常データと比較的多量の正常データを一緒に混ぜて機械学習に使用すると、性能が悪くなる可能性が非常に高いです。 一般的に、異常データが正常データの10%未満の場合、単純分類(classification)機械学習は推奨されません。 異常検知では、異常データが極めて稀であるため、今のところ正常データだけを学習させる教師なし学習が主流です。
今回は、異常検知とは何かについて簡単に紹介しました。 普段、異常検知に興味があった方は少しでも役に立ち、異常検知が何なのかよくわからない方は良い情報を得ることができたと思います!
長い文章を読んでいただきありがとうございました。 😀

NHN Cloud Meetup 編集部