NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2020.01.22
574
TOAST UI Gridは、独自のリアクティブシステムを構築して、データの状態を管理しています。データが変更されると、リアクティブシステムが変更を感知している他のデータ属性も自動更新されるので、データの変更管理が便利に行えます。また、簡単な宣言的コードを使ったり、不要なコードを削減したりできます。しかし、大容量のデータをリアクティブデータに変更すると、パフォーマンスに致命的な影響を与え、Gridの初期レンダリングの速度が低下してしまう問題が発生しました(10万個のデータ基準で、初期レンダリングに約2.5秒の時間を要しました)。ここでは、大容量のデータに対するリアクティブシステムのパフォーマンス問題を解決するため、これまでに導入した方法と検討した内容を、実際のソースコードと共に紹介したいと思います(リアクティブシステムの概念と動作原理については、0.7KBでVueのようなリアクティブシステムを作成するをご参考ください)。
Lazy observableは、実際にリアクティブデータを必要な場合にのみリアルタイムで生成することを意味します。冒頭でお話したように、大容量の配列データをリアクティブデータとして生成するのは予想以上に大きなコストがかかる作業で、これによりGridの初期レンダリングのパフォーマンスが急激に低下しました。問題を解決するため、リアクティブデータの生成に要する時間を短縮する方法を検討しました。まず、初期段階に全データをリアクティブデータに変更するのではなく、オブジェクト範囲を限定して、必要なときに変更してみてはどうかと考えました。最終的に、リアクティブデータに変更するオブジェクト範囲を画面から見えるデータ(スクロール領域内のデータ)に限定して、Lazy observableを適用してみようという結論に至りました。
Lazy observableを理解しやすいように、Gridのサンプル画像と一緒に説明したいと思います。
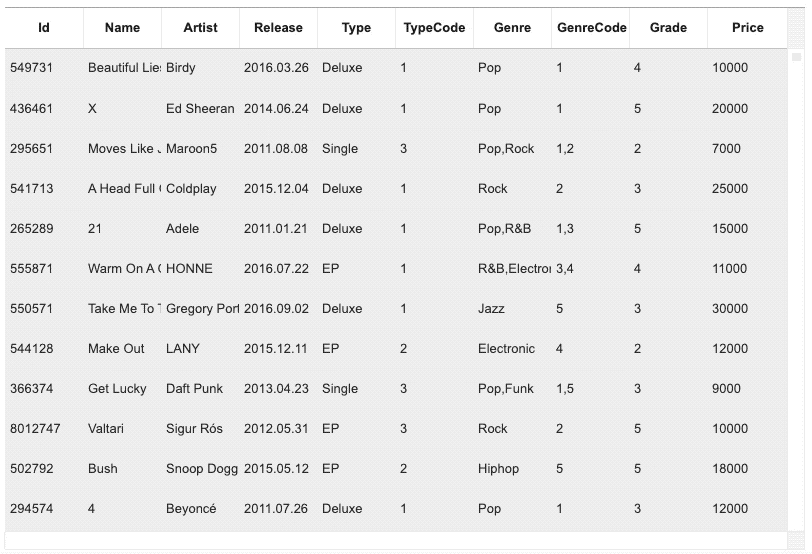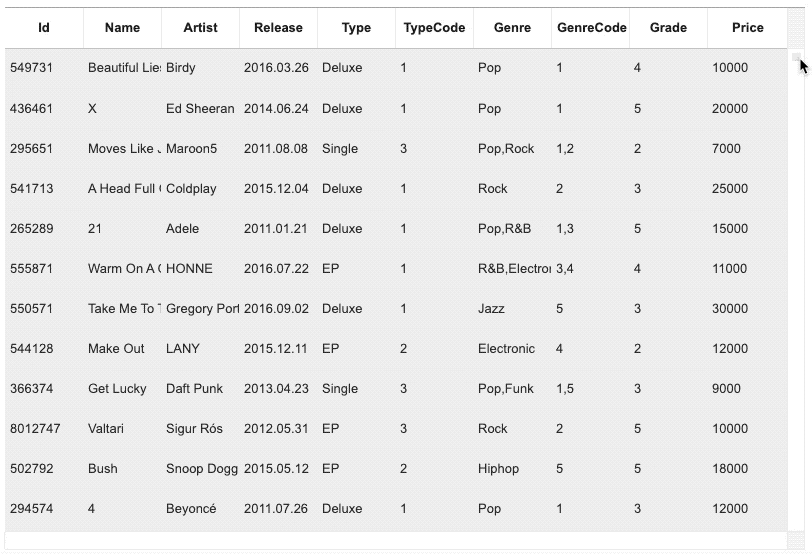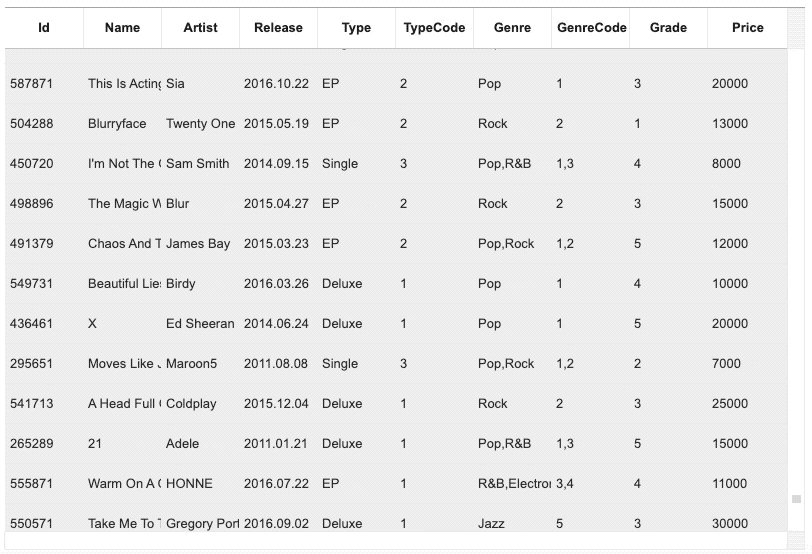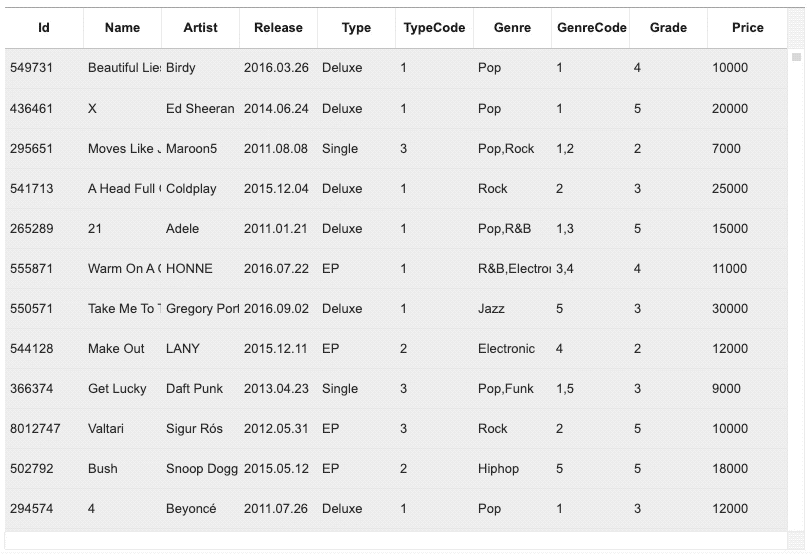
上図は、10万件の大容量データをTOAST UI Gridでレンダリングしたものです。このような場合、すべてのデータをリアクティブデータとして生成する必要があるでしょうか?実際に必要なデータは、スクロール領域内に見える限定的なデータです。それならば、スクロール領域内のレンダリングに必要なデータのオブジェクトだけをリアクティブデータとして生成し、表示されないデータは一般的なオブジェクトの状態で維持した方がはるかに効率的でしょう。これがLazy observableの概念です(Gridはスクロール領域を基準にデータを限定しましたが、この基準はアプリケーションごとに異なるでしょう)。
では、TOAST UI Gridではどのように実装したか、これからコードを見てみましょう。
まず最初に、配列データから、画面に表示するデータ(リアクティブデータに変更するオブジェクト)の範囲を求めます。
function createOriginData(data, rowRange) {
const [start, end] = rowRange;
return data.gridRows.slice(start, end).reduce(
(acc, row, index) => {
// すでにリアクティブデータの場合は含めない
if (!isObservable(row)) {
acc.rows.push(row);
acc.targetIndexes.push(start + index);
}
return acc;
},
{
rows: [],
targetIndexes: []
}
);
}
TOAST UI Gridでは、createOriginData関数を実行してリアクティブデータに変更するオブジェクト範囲を求めます。画面に表示される行範囲に関する情報を持つrowRangeを使って、全体データ(data.gridRows)を基準にリアクティブデータに変更しなければならないrowオブジェクトとindexの情報を返却します。ただし、すでにオブジェクトがリアクティブデータである場合は、新たに生成する必要がないので、isObservable関数を用いて処理します。
元のデータはリアクティブデータではないため、データの変化を感知して自動的に更新することができません。したがって、変更が必要なオブジェクト情報を利用して、元のデータをリアクティブデータに変更する必要があります。
function createObservableData({ column, data, viewport }) {
const originData = createOriginData(data, viewport.rowRange);
if (!originData.rows.length) {
return;
}
changeToObservableData(column, data, originData);
}
function changeToObservableData(column, data, originData) {
const { targetIndexes, rows } = originData;
// リアクティブデータ生成
const gridRows = createData(rows, column);
for (let index = 0, end = gridRows.length; index < end; index += 1) {
const targetIndex = targetIndexes[index];
data.gridRows.splice(targetIndex, 1, gridRows[index]);
}
}
changeToObservableData関数では、originData(createOriginData関数の結果)を用いて、gridRowsというリアクティブデータを生成します。そして既存のデータ(data.gridRows)をspliceメソッドを用いて、新しく生成されたリアクティブデータに変更します。
レンダリングされたデータの範囲が変更されるとき、つまり、スクロールの移動を感知して、自動的に当該範囲のデータをリアクティブデータに変更する作業を行います。
observe(() => createObservableData(store));
createObservableData関数をobserveすると、関数内部で使用されるrowRangeやgridRawsなどが変更される度に自動で再実行され、リアクティブデータ以外のデータを動的に変更してくれます。私たちはすでにobserve関数を実装しているので、上記のコードのように、たった1行のコードでこの部分を自動化することができました。
完成したコードを見てみましょう(実際のコードは、こちらから確認できます)。
/**
* リアクティブデータに変更するオブジェクトのリストを求める
*/
function createOriginData(data, rowRange) {
const [start, end] = rowRange;
return data.gridRows.slice(start, end).reduce(
(acc, row, index) => {
// すでにリアクティブデータの場合は含めない
if (!isObservable(row)) {
acc.rows.push(row);
acc.targetIndexes.push(start + index);
}
return acc;
},
{
rows: [],
targetIndexes: []
}
);
}
/**
* 元のデータをリアクティブデータに変更する
*/
function changeToObservableData(column, data, originData) {
const { targetIndexes, rows } = originData;
// リアクティブデータ生成
const gridRows = createData(rows, column);
for (let index = 0, end = gridRows.length; index < end; index += 1) {
const targetIndex = targetIndexes[index];
data.gridRows.splice(targetIndex, 1, gridRows[index]);
}
}
export function createObservableData({ column, data, viewport }) {
const originData = createOriginData(data, viewport.rowRange);
if (!originData.rows.length) {
return;
}
changeToObservableData(column, data, originData);
}
/**
* レンダリング範囲の変化を感知し、自動でリアクティブデータではなくデータを動的に変更させる
*/
observe(() => createObservableData(store));
実際に、Lazy observableを適用する前後で10万件のデータで検証したところ、Gridの初期レンダリング速度は、2357msと99ms、およそ23倍の速度差がありました。
大容量のデータを扱うアプリケーションでリアクティブシステムを使用しているならば、リアクティブデータを生成する最適化の方法について考慮する必要があります。想像以上にリアクティブデータの生成コストが大きいという点を思い出しましょう。
Batch processingは、大量の反復作業やデータの変更作業を効率的に処理するために広く使用されている方法です。リアクティブシステムで、1つのデータ更新によって連鎖する作業を1つのバッチ単位にまとめ、一度に処理するなどがその例に挙げられます。
Batch processingをリアクティブシステムに適用したときのメリットについて、簡単に調べてみましょう。
リアクティブシステムで特定のデータが変更されると、データを感知している他のデータ属性と算出(computed)属性も連鎖的に変更されます。データの更新が画面のレイアウト作業やリペイント作業を誘発する場合、更新毎に個別に実行するよりは、1つの作業単位にまとめて、不要なレンダリングを誘発する更新プログラムを除去する方法がより効率的です。
リアクティブシステムの欠点があるとすれば、1つの更新によって派生する更新作業の中で重複する作業があっても、簡単に見つけるのが難しく、改善しにくいという点です。しかし、更新作業をバッチ単位でまとめて作業すれば、少なくともバッチ単位別では重複された更新をアンインストールすることができます。
では、実際にTOAST UI Gridで実装しているBatch processingの方法を見ながら説明します(ここではobserve関数の実装方法は説明しません。Batch processingの実装方法を重点的に説明しますので、observe関数の実装方法が知りたい方は、こちらを参照してください)。
function callObserver(observerId) {
observerIdStack.push(observerId);
observerInfoMap[observerId].fn();
observerIdStack.pop();
}
function run(observerId) {
callObserver(observerId);
}
function observe(fn) {
// do something
run(observerId);
}
上のコードは、従来のobserve関数のサンプルです。observe関数が呼び出されると、最初に実行順序を管理するために、observerIdを内部的に管理するスタック(observerIdStack)に蓄積し、observer関数を実行します。この過程で、スタックの最上位にあるobserverIdと関連するもう1つのobserver関数が呼び出され、スタックに蓄積されます。関連作業がすべて完了したら、スタックからobserverIdを順次除去します。
Batch processingを適用して1つの作業単位にまとめてみましょう。
let queue = [];
let observerIdMap = {};
function batchUpdate(observerId) {
if (!observerIdMap[observerId]) {
observerIdMap[observerId] = true;
queue.push(observerId);
}
}
function run(observerId) {
batchUpdate(observerId);
}
変更されたコードを見ると、run関数のobserver関数をすぐに実行するのではなく、batchUpdate関数を呼び出してqueueにobserverIdを入れています。つまり、queueを1つのバッチ単位として見做すことができます。ここで注目すべき点は、observerIdMapというオブジェクトを利用して、queueに入っているobserverIdを重複して入れないように処理している点です。この1行のコードで重複した更新を防ぐことができます。
queueに含まれるobserver関数を実行するflushという関数を作成すると、最終的なコードは次のようになります。
let queue = [];
let observerIdMap = {};
let pending = false;
function batchUpdate(observerId) {
if (!observerIdMap[observerId]) {
observerIdMap[observerId] = true;
queue.push(observerId);
}
if (!pending) {
flush();
}
}
function callObserver(observerId) {
observerIdStack.push(observerId);
observerInfoMap[observerId].fn();
observerIdStack.pop();
}
function clearQueue() {
queue = [];
observerIdMap = {};
pending = false;
}
function flush() {
pending = true;
for (let index = 0; index < queue.length; index += 1) {
const observerId = queue[index];
observerIdMap[observerId] = false;
callObserver(observerId);
}
clearQueue();
}
batchUpdate関数が実行されると、pendingという変数を見てflush関数を実行します。もし同じバッチ内で、すでにflush関数が実行されている場合(pending変数の値がtrue)には、queueにobserverIdだけを入れておき、flush関数は実行しません。この部分が重要です。派生した更新が漏れなく正しく実行されるには、pending状態のときもobserverIdをqueueに入れています。そして、flush関数内のfor文で、動的に増加するqueueの長さを反映してobserver関数を実行します。
最近使用されている多くのフレームワークやライブラリ(React、Vue、Preactなど)で、すでにDOMレンダリングに関連した最適化が行われています。しかし、Batch processingを追加すると、レンダリングの最適化よりも前に不要な演算を防止することができます。
TOAST UI Gridは、配列データをリアクティブデータとして生成していません。リアクティブデータの生成コストは予想以上に大きく、配列が大きい場合ではこのような作業が非常に負担になるからです。
従来のTOAST UI Gridは、配列データの更新が必要なときに、notify関数を直接呼び出し、配列の属性に関連したobserve関数を強制的に呼び出すように処理していました。初期のGridではnotify関数だけで問題ありませんでしたが、新しい機能を追加するにつれて、notify関数を呼び出す重複コードが多くなってしまう問題が生じました。重複コードが多いということは、コードの品質が低下することも意味します。私たちはコードの品質向上のため、notify関数を呼び出すことなく、配列データに関連するobserve関数を自動的に呼び出す方法について検討しました。そしてMonkey patch方法を活用して、問題の解決を試みました(Monkey patchは、特定のオブジェクトの属性やメソッドを動的に変更することを意味します。詳しい内容はリンクをご参照ください)。
では、Monkey patchを活用して、どのように問題を改善したか一緒に見てみましょう。
TOAST UI Gridは更新が必要な配列データが多くなるほど、関連するobserve関数を呼び出すためにnotify関数を実行します。次のサンプルコードを見てみましょう。
function appendRow(store, row) {
// do something
rawData.splice(at, 0, rawRow);
viewData.splice(at, 0, viewRow);
heights.splice(at, 0, getRowHeight(rawRow, dimension.rowHeight));
// notify呼び出し部分
notify(data, 'rawData');
notify(data, 'viewData');
notify(data, 'filteredRawData');
notify(data, 'filteredViewData');
notify(rowCoords, 'heights');
}
上のコードを見ると、notify関数の呼び出しが繰り返されていることが分かるでしょう。パフォーマンスには全く問題ありませんが、コードが重複しているため、appendRowのように配列データの変更がある関数が多くなればなるほど、重複コードは追加されることでしょう。
Monkey patchの対象は配列データであり、その目的は配列データの更新を自動で感知して、関連するobserve関数が実行されるようにすることです。したがって、配列データの更新を発生させる特定のメソッド(splice、push、popなど)のみ、ラッピング対象となり、それ以外の単純な照会や新しい配列オブジェクトを返却するメソッドについては、作業を行う必要がありません。
更新を発生させるメソッドをどのようにラッピングしたか、コードと共に見てみましょう。
const methods = ['splice', 'push', 'pop', 'shift', 'unshift', 'sort'];
export function patchArrayMethods(arr, obj, key) {
methods.forEach(method => {
const patchedMethods = Array.prototype[method];
// 既存メソッドをpatch関数でMonkey patchする
arr[method] = function patch(...args) {
const result = patchedMethods.apply(this, args);
notify(obj, key);
return result;
};
});
return arr;
}
patchArrayMethods関数内部のループには、配列データを更新した後、自動的にnotify関数を呼び出すpatch関数が宣言されています。そして、あらかじめ定義されたmethods変数を使って、配列(arr)の属性をpatch関数としてMonkey patchする作業をしています。
Array.prototypeを直接操作して変更しても良いのですが、他のアプリケーションに意図しないバグやサイドエフェクトを発生させてしまうことがあるため、この方法ではなく、それぞれの配列オブジェクトを対象にMonkey patchする方法を選択しました。
Monkey patchを適用したコードを見て、どのような変化があったのか確認してみましょう。
function setValue(storage, resultObj, observerIdSet, key, value) {
if (storage[key] !== value) {
if (Array.isArray(value)) {
patchArrayMethods(value, resultObj, key);
}
storage[key] = value;
Object.keys(observerIdSet).forEach(observerId => {
run(observerId);
});
}
}
export function observable(obj) {
// do something
Object.keys(obj).forEach(key => {
// do something
if (isFunction(getter)) {
observe(() => {
const value = getter.call(resultObj);
setValue(storage, resultObj, observerIdSet, key, value);
});
} else {
storage[key] = obj[key];
if (Array.isArray(storage[key])) {
patchArrayMethods(storage[key], resultObj, key);
}
Object.defineProperty(resultObj, key, {
set(value) {
setValue(storage, resultObj, observerIdSet, key, value);
}
});
}
});
return resultObj;
}
function appendRow(store, row) {
// do something
rawData.splice(at, 0, rawRow);
viewData.splice(at, 0, viewRow);
heights.splice(at, 0, getRowHeight(rawRow, dimension.rowHeight));
}
上記コードのように、observable関数のリアクティブデータの属性タイプが配列である場合、patchArrayMethodsを呼び出して配列のメソッドをラップすると、その配列データが更新される際に自動的に関連するobserve関数が呼び出されます(observable関数の全体ソースコードはこちら)。強制的にobserve関数を実行するためにnotify関数を呼び出す必要がなくなりました。appendRow関数を見ると、重複するnotify関数がすべて削除され、はるかにきれいに修正されたことが分かります。
ここまで、TOAST UI GridでリアクティブシステムにMonkey patchを適用した理由とその方法について、コードを見ながら簡単に説明しました。重複したコードを取り除き、非常にすっきりとしたコードでリファクタリングすることができ、コードの品質も向上できました。
Lazy observableで説明したコードをベースに、先の内容を整理してみましょう。
function changeToObservableData(column, data, originData) {
const { targetIndexes, rows } = originData;
// リアクティブデータ生成
const gridRows = createData(rows, column);
for (let index = 0, end = gridRows.length; index < end; index += 1) {
const targetIndex = targetIndexes[index];
data.gridRows.splice(targetIndex, 1, gridRows[index]);
}
}
export function createObservableData({ column, data, viewport }) {
const originData = createOriginData(data, viewport.rowRange);
if (!originData.rows.length) {
return;
}
changeToObservableData(column, data, originData);
}
observe(() => createObservableData(store));
上のコードは、スクロールが移動するとき、画面のレンダリングに必要なデータをリアクティブデータに更新してくれるコードです。繰り返し処理のコードを詳しく見てみましょう。
for (let index = 0, end = gridRows.length; index < end; index += 1) {
const targetIndex = targetIndexes[index];
data.gridRows.splice(targetIndex, 1, gridRows[index]);
}
Grid内の配列データはリアクティブデータで作られていないため、splice、pushと同じ関数でデータを更新しても、notifyのような関数を呼び出さなければ更新が発生しません。しかし、Monkey Patching Arrayで見たように、配列メソッドをラップしたため、自動更新が発生します。
ここで、次のような疑問が生じるかもしれません。for文の中でspliceメソッドを呼び出すために、毎回配列データが更新され、派生する更新が実行されると、問題になるのではないでしょうか?
この点は、Batch processingを実装してあるので、心配ありません。
observe(() => createObservableData(store));
リアクティブデータを生成(createObservableData)する関数がobserve関数内で呼び出されます。つまり、for文内から派生する更新は、すべて1つのバッチジョブ単位にまとめられるので、繰り返し文の度に即時更新したり、重複する更新は発生しません。
ここまで全体的な流れを簡単に説明しました。省略されたコードを見たい方は、GitHubをご確認いただければと思います。
リアクティブシステムは非常に便利なシステムです。observe関数を用いて自動的にデータとビュー(View)の更新を行ってくれます。しかし、このような使い勝手の良さに慣れてしまい、毎回更新する必要がないデータまでもリアクティブデータとして登録して開発を行うケースがあります。
const obj = observable({
start: 0,
end: 0,
get expensiveCalculation() {
let result = this.start + this.end;
// ... do expensive calculation
return result;
}
});
obj.start = 1;
obj.end = 1;
上記のサンプルで、expensiveCalculationという非常に複雑な演算を実行する算出(computed)属性が、リアクティブデータとして生成される、と仮定してみましょう。この属性は、startまたはend属性が変更される度に、複雑な演算を伴って自動更新される必要があります。このような場合、expensiveCalculationが毎回更新されるほど頻繁に使用される属性に値するのか、考えてみなければなりません。そうでなければ、expensiveCalculationは必要な場合にのみ、別の関数に分離して呼び出す方が、はるかに効率的でしょう。
TOAST UI Gridのように、大容量のデータを扱うアプリケーションのパフォーマンスは非常に重要な部分です。パフォーマンスに影響を与える要因と改善策は色々ありますが、私たちはリアクティブシステムの性能改善に重点を置きました。そして最適化に向けた3つの方法を、実際のTOAST UI Gridの適用コードを見ながら調べました。これらの方法は、Gridに限った方法ではなく、リアクティブシステムの改善に向けてどこにでも適用できる方法です。
TOAST UI Gridはv4配布後も、様々な機能追加やパフォーマンス問題を解決するために、数多くの変化を経験しました。今後もたくさんの方々が便利に利用できるように、TOAST UI Gridはさらに進化していきたいと思います。ご不明な点やご要望があれば、GitHub issueにぜひ残してください。


NHN Cloud Meetup 編集部