NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2019.10.07
4,043
確率的データ構造であるブルームフィルター(Bloom filter)は、ストレージを節約できる上、高速検索ができるため、HBase、Redisなど様々なデータベースで活用されているという話をよく聞きます。実際にどのように活用され、どのような原則でデータを含蓄的に表現できるかを簡単に説明した後、実際のデータ処理環境でどのように使用されているか、サンプルを使って紹介しようと思います。
ブルームフィルターを簡単に説明すると、次のように言えます。
「どのような値が集合に属しているかをチェックするフィルタ、及びこれを構成するデータ型」
この構造を図式化してみましょう。
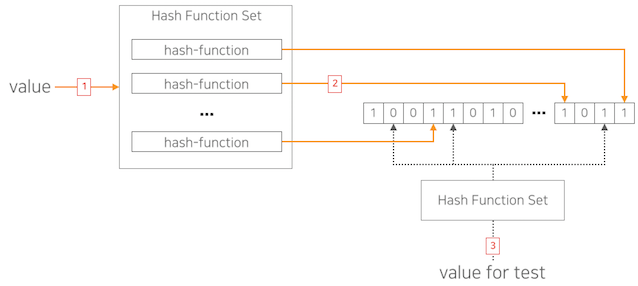
保存したい集合の値をn個のハッシュ関数(hash function)を経るようにして(1)、出力された各ビットをビットマップ配列に保存(2)します。
すべての値に対して、このプロセスを経ると、最終的に保存が必要な元素の集合データ(dictionary)が生成されます。
このように保存されたデータに、どのような値が属しているか確認する過程は、図の(1)(2)と似ています。
検査用の値は、ハッシュ関数を経てビットマップで表現され、このビットマップと作成したdictionaryを論理演算し、自分のビットマップが出力されるとdictionaryに含まれていると判断する仕組みです。
データ量が膨大であってもビットマップでデータを保存するので、保存空間を大幅に節約できますが、ハッシュ衝突が起きて、存在しない値を「ある」と誤検知することもあります。(False Positive)
これを解決するため、ハッシュ関数の本数とビットマップサイズを調節して、精度を高めることができます。
このような公式を、ソースで次のように簡単に実装できます。
package com.airguy.mr.paycouser;
import org.apache.hadoop.util.bloom.BloomFilter;
import org.apache.hadoop.util.bloom.Key;
import org.apache.hadoop.util.hash.Hash;
public class DTLFilter {
private BloomFilter BF = null;
public DTLFilter(int RecordNum) {
int vector_size = getOptimalVectorSize(RecordNum, 0.01f);
int function_size = getOptimalFunctionSize(RecordNum, vector_size);
BF = new BloomFilter(vector_size, function_size, Hash.MURMUR_HASH);
}
public int getOptimalVectorSize(int numRecords, float falsePosRate) {
int size = (int) (-numRecords * (float) Math.log(falsePosRate) / Math.pow(Math.log(2), 2));
return size;
}
public int getOptimalFunctionSize(float numMembers, float vectorSize) {
return (int) Math.round(vectorSize / numMembers * Math.log(2));
}
public void add(String key) {
BF.add(new Key(key.getBytes()));
}
public boolean contain(String key) {
return BF.membershipTest(new Key(key.getBytes()));
}
}
「1年分のユーザー履歴のうち、特定サービス(以下「Aサービス」)のユーザーを除いて抽出してほしい」という依頼があったとしましょう。
通常、このような結合操作の場合、小さいものを配布して処理するブロードキャスト結合や、マップサイドジョインを実行することになりますが、小さいものである「Aサービスのユーザーリスト」が非常に大きなサイズであれば、通常の作業では処理できません。
そこで、次のようなフローで作業を構成してみましょう。

似たような例として、ユーザー別の使用履歴を照会する必要がある場合、通常は次のように保存します。
| ユーザーID | 使用履歴 |
|---|---|
| ユーザー1 | 履歴コードカテゴリ1 |
| ユーザー1 | 履歴コードカテゴリ2 |
| ユーザー1 | 履歴コードカテゴリ3 |
| ユーザー2 | 履歴コードカテゴリ1 |
| ユーザー2 | 履歴コードカテゴリ2 |
| … |
あるいは
| ユーザーID | 使用履歴 |
|---|---|
| ユーザー1 | 履歴コード1、履歴コード2、履歴コード3 … |
| ユーザー2 | 履歴コード1、履歴コード2 |
| … |
このデータを用いてすべてのユーザー履歴を照会するとき、従来のリレーショナルデータベース(RDB)では、ユーザーカラムにインデックスを追加する方法でフルスキャンを回避しますが、履歴を照会する場合は、データ量が大きいデータ型のため、インデックスをかけるにも比較演算するにもコストが大きくなります。
そこで、次のような型に変換し、これを再生できるUDFを作成して使用します。
| ユーザーID | 使用履歴 |
|---|---|
| ユーザー1 | ユーザー1の履歴 Bloom filter |
| ユーザー2 | ユーザー2の履歴 Bloom filter |
| … |
容量が1/2〜1/4程度に減少しましたが、より重要な実際の駆動速度を比較すると、このようになりました。
 処理速度が約1/10に減少しました。
処理速度が約1/10に減少しました。
しかし、結果から分かるように若干の誤差があります。
前述のFalse Positive性質のため「ない」履歴を「ある」と言う場合があります。誤差率を0.01%に設定して生じた誤差ですが、より正確に設定すると、容量と処理時間が一緒に増える代償があります。
正確性をあまり重要視しない、おおよその数値をすぐに知りたいときに便利なケースであると言えるでしょう。
ブルームフィルターは、処理性能比較が少ないメモリ空間を必要とする利点のため、データベース以外にも多くの場所で使用されています。仮想通貨、IPフィルタリング、辞書(+スペルチェック)、ルーター、Chromeブラウザ(マルウェアサイトか? -ブラックリスト)が良い例でしょう。
1億ユーザー単位のサービスでも、新規ユーザーを確認する際、100メガ程度のメモリだけを使って、マイクロ秒単位で応答するような検証マシン、そんな環境を実現してみるはいかがでしょうか。


NHN Cloud Meetup 編集部