NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2016.02.17
2,106

(出典:Wikipedia)
1、2編では、Cassandraが分散されたデータをどうのように入出力するかを中心に調べましたが、今回はCassandraがサポートする機能とCassandraを使用するときに便利なPattern、なるべく避けるべきAnti-Pattern、そしてまだ説明できていなかった内容について、いくつか紹介したいと思います。
Cassandraは、Gossipプロトコルを用いてすべてのノードが等しいRing構造になっており、これによって効果的なデータ分散と高いScalability、High Availabilityを実現していますが、ご存知のようにすべての点において完全なソリューションではありません。多くのNoSQL製品がそうであるようにCassandraもJoinやTransactionをサポートしておらず、高レベルのIndexも提供していません。CassandraがサポートするIndexは、先に述べたRow Keyを検索する基本的なIndexと0.7バージョンから追加されたSecondary Indexというささやかな機能だけです。(Secondary Indexは後で説明します)ここでは、Cassandraの特徴的な機能を調べて、これらの機能がどのような特徴を持っているか探ってみましょう。
名前から推測できるように、Light-Weight Transactionは非常に簡単でありながら軽さを支援する小さな範疇のTransaction機能です。サービス開発では、重複してはならないなど、一貫性を維持する必要があるデータを取り扱うときがあります。Light-Weight Transactionはこのようなときに便利な機能で、特定の条件に合わせてデータを操作できます。つまり、Compare and Setに限定されたTransactionなのです。使用方法は比較的簡単で、InsertとUpdate構文でIF文を利用することで使用できます。簡単な例を挙げてみましょう。まず、以下のようなTableがあると仮定して、1つのデータをInsertしてみましょう。
CREATE TABLE test_keyspace.test_table_ex_1 ( id text PRIMARY KEY, name text, descript text ); INSERT INTO test_keyspace.test_table_ex_1 (id, name , descript ) VALUES ( 'id_1', 'name_1', 'test_data'); SELECT * FROM test_keyspace.test_table_ex_1;
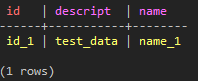 (図1:1つのデータが入っている)
(図1:1つのデータが入っている)
前回の記事で述べたように、基本的にCassandraはInsertとUpdateが内部では事実上同じ動作となるため、以下のようなクエリを実行する場合、RDBMSとは異なり問題なくデータを修正できます。
INSERT INTO test_keyspace.test_table_ex_1 (id, name , descript ) VALUES ( 'id_1', 'name_1', 'test_data_2'); SELECT * FROM test_keyspace.test_table_ex_1;

(図2:Insertを実行したにもかかわらず、クエリ文が実行されてdescriptionを修正してしまった)
このようなCassandraの特徴は、様々な問題を発生させます。正しくInsertしないと既存のデータが失われてしまいます。特に重複して存在してはならない種類のデータであれば、なおさら問題になるでしょう。では、これから同じクエリ文にIF NOT EXISTSを付けて実行してみましょう。
INSERT INTO test_keyspace.test_table_ex_1 (id, name , descript ) VALUES ( 'id_1', 'name_1', 'test_data_3') IF NOT EXISTS;
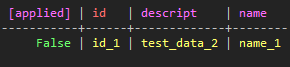
(図3:appliedというColumnはデータのクエリが成功するかどうかを表す)
すでに存在している値があるため、データを変更せずにクエリの動作が失敗したことがわかります。では、実質的にInsertと同じUpdateもLight-Weight Transactionは提供されないでしょうか?当たりです。ただしUpdateはInsertとは少し違う形で、下記のような構文を使って機能を提供します。
UPDATE test_keyspace.test_table_ex_1 SET descript='test_data_3' WHERE id = 'id_1' IF name = 'name_1';
 (図4:name columnが「name_1」である場合にのみ、クエリが正常に実行される)
(図4:name columnが「name_1」である場合にのみ、クエリが正常に実行される)
このようにInsertとUpdateに限って提供されるLight-Weight Transactionは、Transactionを提供できないCassandraでは便利に使用できる機能です。しかし、文法的に提供されるQueryの自由度が依然として低い水準であり、Light-Weight Transaction自体を濫用するとパフォーマンスの低下を招きかねず、必要な場所で適宜使用することが重要です。
Secondary IndexはCassnadra 7.0以降、検索用に追加されたシンプルな機能です。基本的にCassandraはPartition Key(Row Key)にデータを分散してCluster Key(あるいはColumn Name)でRow内のデータをソートしているため、この2つのKeyで指定されたCQL ColumnのDataは、CQLのWhere構文を使った検索が可能ですが、そうではないCQL Columnについては検索する方法がありませんでした。そのため、多くのCassandraのユーザーは、データの非正規化を用いて問題を解決してきました。
![]() (図5:検索結果が出ない)
(図5:検索結果が出ない)
しかし、Secondary Indexを作成した後、同じQueryを実行すると、これらの問題は簡単に解決できます。
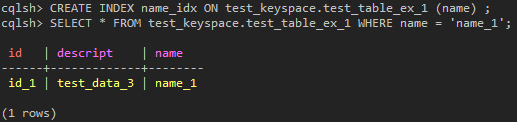 (図6:Where文Partition keyの情報がなくても簡単に検索できる)
(図6:Where文Partition keyの情報がなくても簡単に検索できる)
Secondary Indexがない場合は、必要なデータを得るために必ずPartition KeyとCluster Keyを使って検索することになります。特定のCQL ColumnにSecondary Indexを作成して使用する場合は、CQL Columnに対して必要なデータをいくらでも検索できるようになりました。
![]() (図7:「>」のようなRange Queryは動作しない)
(図7:「>」のようなRange Queryは動作しない)
もちろん、多くの方が予想されるように、これも万能キーではありません。Secondary Indexは、Range Queryに対応していないため、「=」とContainsのような文法を用いた限定的な検索のみ可能で、さらに濫用してはいけないパフォーマンス上の理由が明確に存在します。この部分についは少し後でお話します。
Cassandraを使っていると、まれに2つ以上の動作を一度に実行する必要性を感じることがあります。もちろん、この動作に対するTransactionが保証されていればよいのですが、ご存知のようにCassandraはTransactionに対応していません。その代わり、Transactionの4つの要素(ACID)の中で、Atomicの動作だけを保証する機能があります。それがまさしくBatchと呼ばれる機能です。
Batchは、複数のQueryドアを一度にまとめて1回で実行でき、その動作に対して必ずAll or Notingの結果を保証します。ただし、Batchの性能はやや遅く、Transactionを確保する機能がないことを理解した上で使用しましょう。
初期のCassandraにはSuper ColumnとSuper Column Familyという概念がありました。CassandraのColumn Valueに再度Columnデータを入れたものをSuper Columnと呼び、これらのSupser Columnタイプのデータを持つColumn FamilyをSuper Column Familyと呼びました。これは、スキーマを構成する上で非常に便利な面がありましたが、使用上では複雑な概念でした。幸いなことに、この2つの概念は、Cassandra 1.2から廃棄され、その後はCollectionに置き換えられました。(もちろん既存バージョンとの互換性のため、Super ColumnとSuper Column Familyを使用すると内部的にはCollectionに保存される形式に変更されました。)
Collectionは名前からもわかるように、Set、List、Mapの3つのタイプに分けられます。実際のデータが入力されるValue値は64KBでサイズが制限されています。しかし、これよりもさらに注目すべき点は、このような3つのタイプのデータが実際のCassandra Data Layerで、どのように保存されるのかということです。順番に見てみましょう。
Create TABLE test_keyspace.test_table_set (name text PRIMARY KEY , data set);
INSERT INTO test_keyspace.test_table_set (name, data ) VALUES ( 'eom', {'1', '1', '1'} );
SELECT * FROM test_keyspace.test_table_set;
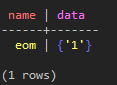 (図8:Setの特性上、1つの1の値だけ保存されたことが分かる)
(図8:Setの特性上、1つの1の値だけ保存されたことが分かる)
まずSetをColumnに持つTableを作成してデータをInsertした後、Select文でみると、上記のような結果になります。CQL上でSetタイプの材料は極めて常識的に保存されたことが分かりますね。では、実際のデータ形式を表示するcliユーティリティからこのデータをインポートすると、どのように表現されるでしょう?
use test_keyspace; list test_table_set;
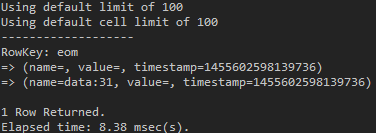 (図9:data:とある数字はsetに属するStringの16進数のbyte値である)
(図9:data:とある数字はsetに属するStringの16進数のbyte値である)
Setタイプで指定されたCQL Column名に “:” を付けた後、実際のデータの16進数に変換した値をColumn Nameで使用します。そして該当するColumnのValueは空であることが分かります。今回はListがどうなるでしょうか?
Create TABLE test_keyspace.test_table_list (name text PRIMARY KEY , data list); INSERT INTO test_keyspace.test_table_list (name, data ) VALUES ( 'eom', ['1', '1', '1']); SELECT * FROM test_keyspace.test_table_list;
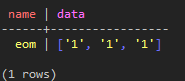 (図10:Listの特性上、すべての1の値が格納されました)
(図10:Listの特性上、すべての1の値が格納されました)
use test_keyspace; list test_table_list;
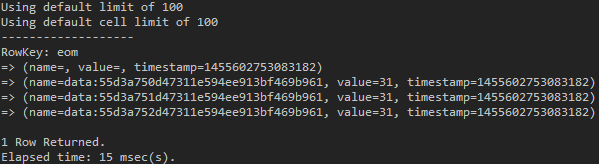 (図11:”data:”がついている文字列はCassandraが発行したUUIDである)
(図11:”data:”がついている文字列はCassandraが発行したUUIDである)
重複データを含むことができるListの特性から、Setとは異なり、Column NameはCassandraが発行したUUIDで占められます。そして、実際のListに挿入したデータは、ColumnのValueに入っていることを確認することができます。このようにSetとListを見てみると、Mapがどのように保存されるかが大体理解できます。しかし正確に確認するため、Mapも一度テストしてみましょう。
Create TABLE test_keyspace.test_table_map (name text PRIMARY KEY , data map);
INSERT INTO test_keyspace.test_table_map (name, data ) VALUES ( 'eom', {'1':'sejin', '1':'sejin', '2':'duron'});
SELECT * FROM test_keyspace.test_table_map;
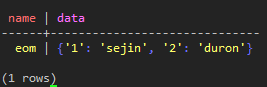 (図12:keyが重なる1の値は1つしか格納されないことが確認できる)
(図12:keyが重なる1の値は1つしか格納されないことが確認できる)
use test_keyspace; list test_table_map;
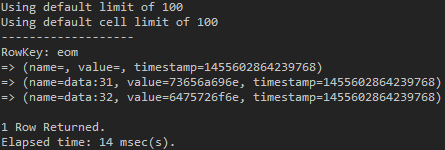 (図13:mapのkeyはColumn Nameに、valueはColumn Valueに保存された)
(図13:mapのkeyはColumn Nameに、valueはColumn Valueに保存された)
Setのような特性を持つMapのKeyはColumn Nameに「:」の文字と一緒に保存され、Listと同じ特性を持つMapのValueはColumn Valueに保存されたことが分かります。
このようにCassandraの内部でCollectionが実際にどのように保存されるか簡単に紹介しました。これらの内容を必ずチェックしなければならない理由は、実際のデータの保存方法を考慮せずにCassandra Tableのスキーマを作成すると、時折パフォーマンスの問題を引き起こすことがあるからです。例えば、以前の内容から推測できるように、Collectionに絶えずデータを挿入してしまうと、Cassandraに保存されているRowの長さだけ増え続け、Cassandraの最大の利点であるデータ分散が行われず、加えてHotspotのリスクが高くなるなど、様々なリスクを生じる可能性があります。したがって、データが実際にどのように保存されるのか理解するのは、思ったよりも重要なことです。
前回の記事を振り返ると、Cassandraの大きな特徴は、すべてのノードが等しいRing形態である分散システムで、データを使って読むのに優れた利点を持っているシステムであると要約できます。ここからは広く知られている内容を中心に、Cassandraをどのように使用すべきか、1つずつ調べてみましょう。
私たちは、CassandraがPartition Key(Row Key)単位でデータを分散し、1つのPartition Key内のデータをSSTableというストアに既に配置された状態で記録させる、ということを知っています。また、Cassandraは優れた分散型構造から、たくさんのデータの書き込み、読み込みに適していますが、Tombstone方式により大量データのDeleteはあまり適していない、ということを知っています。では、Cassandraはどこに用いるとよいでしょう?どうやらSNSやLog Dataなどの保存には向かないようです。これらのデータは、時間順に蓄積するという特徴を持っています。
次のようなサービスを想定してみましょう。5分間隔で各サーバーの実際のユーザー数とサーバーの状態を記録する必要があるとします。これらの記録性のデータは、どのような形式で保存するとよいでしょうか?分散させるデータはサーバー単位で割るとよいようですが、Partition keyはおそらくServer IDに適合し、それぞれのデータは5分間隔で一定に保存されるため、Cluster KeyとしてはTimestampが適切ではないでしょうか。実際にTableを作成し、5分間隔で4回のデータが収集されたと仮定して、データを入れてみましょう。
CREATE TABLE test_keyspace.test_ts ( serverId TEXT, timestamp INT, data TEXT, PRIMARY KEY ( serverId, timestamp ) );
INSERT INTO test_keyspace.test_ts ( serverId, timestamp, data ) VALUES ( 'server_1', 1455194927, '{ "userNumber" : 100, "serverStatus" : "STABLE" }' );
INSERT INTO test_keyspace.test_ts ( serverId, timestamp, data ) VALUES ( 'server_1', 1455195227, '{ "userNumber" : 105, "serverStatus" : "STABLE" }' );
INSERT INTO test_keyspace.test_ts ( serverId, timestamp, data ) VALUES ( 'server_1', 1455195527, '{ "userNumber" : 100, "serverStatus" : "STABLE" }' );
INSERT INTO test_keyspace.test_ts ( serverId, timestamp, data ) VALUES ( 'server_1', 1455195827, '{ "userNumber" : 95, "serverStatus" : "STABLE" }' );
SELECT * FROM test_keyspace.test_ts;
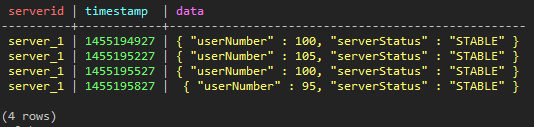 (図14:データを入れた直後の結果。合計4つのデータが保存された)
(図14:データを入れた直後の結果。合計4つのデータが保存された)
このように入ったデータはCQLだけを見ても使い勝手が非常に快適なようです。サーバーIDに基づいてCassandraノード別にデータが分散されることで、分散されたデータの中ではCluster Key基準にデータが配置されて保存されます。したがってWHERE文とtimestampを使ってRange queryも使用できますね。正確に確認するため、cliユーティリティを使ってデータが実際にどのように保存されているか見てみましょう。
use test_keyspace; list test_ts;
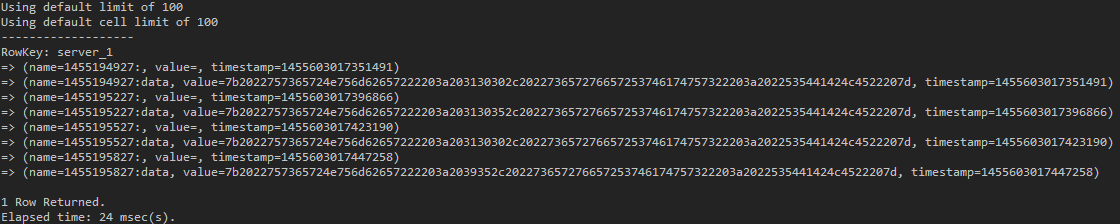 (図15:この時点で、各Columnに含まれているtimestampは、私たちがCQL Columnに指定したCQL Column timetampではなく、cassandraが内部的に使用される。すべてのColumnに基本的に付けるtimestampなので混同していけない)
(図15:この時点で、各Columnに含まれているtimestampは、私たちがCQL Columnに指定したCQL Column timetampではなく、cassandraが内部的に使用される。すべてのColumnに基本的に付けるtimestampなので混同していけない)
期待通りサーバーIDはRow Keyとなり、Cluseter Keyで指定したtimestampのvalue値に残りのCQL Column名に “:” が付いてCassandra Data LayerのColumn Nameとなったことが分かります。data CQL Columnに保存されたデータは、16進数byte arrayに変換されて保存されたことが分かります。
この方式のスキーマは、1つ問題があります。このままでは時間が経つにつれ、サービスが保存するデータが増え続けるでしょう。データを分散する基準は、Partition Key(Row Key)のため、1つのサーバーIDに対応するすべての時間に関するデータは、たった1つのPartition Keyを基準に保存されるでしょう。最終的には、Partition Keyを担当しているノードがHotspotになる可能性も高くなるでしょうし、Rowの長さが長くなればなるほど、検索、削除のパフォーマンス低下につながります。これはCassandraの代表的なAnti-Patternの1つで、Rowが無期限に長くなるような方式のスキーマ構成は避けましょう。
では、どのような方法でスキーマを設計すればよいでしょうか。100%正しい答えはありませんが、以下のようなテーブルを作成して同じ形式のデータを入れてみましょう。ただし、timebounderyは毎時間、定刻のtimestamp値を入れるようにします。(例:1455192000 = 2016.2.11. 21:00:00、1455195600 = 2016.2.11. 22:00:00)
CREATE TABLE test_keyspace.test_ts_2 ( serverId TEXT, timeboundery INT, timestamp INT, data TEXT, PRIMARY KEY( (serverId, timeboundery), timestamp ) );
INSERT INTO test_keyspace.test_ts_2 ( serverId, timeboundery, timestamp, data ) VALUES ( 'server_1', 1455192000, 1455194927, '{ "userNumber" : 100, "serverStatus" : "STABLE" }' );
INSERT INTO test_keyspace.test_ts_2 ( serverId, timeboundery, timestamp, data ) VALUES ( 'server_1', 1455192000, 1455195227, '{ "userNumber" : 105, "serverStatus" : "STABLE" }' );
INSERT INTO test_keyspace.test_ts_2 ( serverId, timeboundery, timestamp, data ) VALUES ( 'server_1', 1455192000, 1455195527, '{ "userNumber" : 100, "serverStatus" : "STABLE" }' );
INSERT INTO test_keyspace.test_ts_2 ( serverId, timeboundery, timestamp, data ) VALUES ( 'server_1', 1455195600, 1455195827, '{ "userNumber" : 95, "serverStatus" : "STABLE" }' );
SELECT * FROM test_keyspace.test_ts_2;
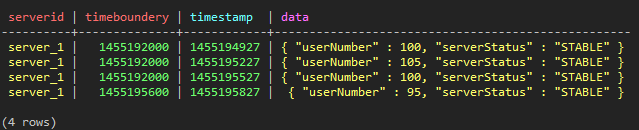 (図16:CQLで表現されたデータを掲載)
(図16:CQLで表現されたデータを掲載)
use test_keyspace; list test_ts_2;
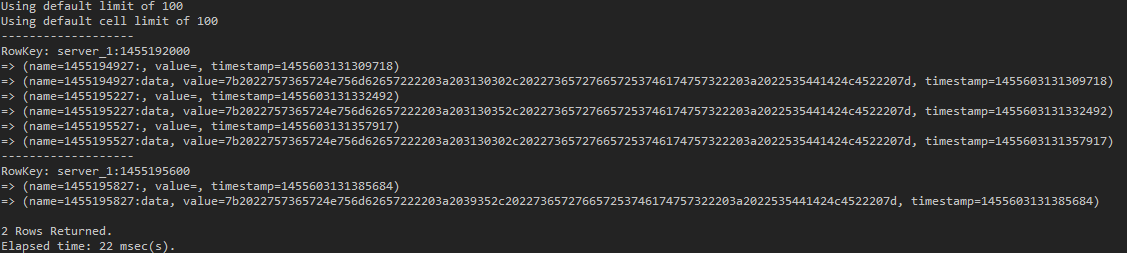 (図17:’serverId’:’timeboundery’の形でRow Keyが指定されたことが分かる)
(図17:’serverId’:’timeboundery’の形でRow Keyが指定されたことが分かる)
これは1時間毎にtimebounderyを指定してPartition Keyに用いるようにしたので、データはServerIdとtimebounderyの組み合わせで分散されるということが上の結果から分かります。このような構造では、次のような方法でデータを取得できるでしょう。server_1サーバーの2016/2/11 09:00から22:00までの記録を検索してみましょう。
SELECT * FROM test_keyspace.test_ts_2 WHERE serverId='server_1' AND timeboundery = 1455192000;
 (図18:9:00:00から21:59:59までの記録)
(図18:9:00:00から21:59:59までの記録)
もう少し詳しくserver_1サーバーの2016/2/11 9:00から21:50までの記録を検索します。
SELECT * FROM test_keyspace.test_ts_2 WHERE serverId='server_1' AND timeboundery = 1455192000 AND timestamp < 1455195000;
 (図19:2016/2/11 21:48:47のデータだけを検索した)
(図19:2016/2/11 21:48:47のデータだけを検索した)
Time Sequencialなデータを一定の長さに切ってすべてのノードに均等に分散できるようになりました。また必要なデータを大きな制約なく検索して取得することもできます。このように、データの長さが無限に長くなるとき適当に分割できるようにPartition keyを指定するのは、スキーマを設計する上で非常に重要な要素の1つです。
CassandraはJoinに対応していないで、高水準のIndexにも対応していません。そのためデータを希望する方式で取得するには多くの制約がありました。よってある程度の使用性を満足させるため、多くの人々はデータを非正規化して管理してきました。もちろん0.7バージョン以降にSecondary Indexを用いてある程度検索の自由度を高めることができましたが、根本的な解決策にはなりませんでした。このためCassandraでの非正規化は、依然として多くの方々がよく使う手法として存在します。簡単な例を挙げましょう。
CREATE TABLE test_keyspace.test_worker ( name TEXT PRIMARY KEY , job TEXT );
Secondary Indexはいったん論外として、上記のようなテーブルでは、nameに基づいてjobデータを読み込むことはできますが、jobを使ってnameを検索することは不可能です。このようなときCassandraでは、次のようなテーブルを作成してデータを管理すると、すぐに解決できるでしょう。
CREATE TABLE test_keyspace.test_job ( job TEXT PRIMARY KEY , name TEXT );
もちろん、結果的に同じデータが重複して管理されているわけですが、JoinやIndexをサポートしないCassandraにおいては、非常に日常的なことです。Diskにかかる費用はメモリやCPUのような他リソースに比べて最も安いことを考えると、これは当然の結果とも言えるでしょう。Cassandraを使用する際には、RDBMSとは異なり非正規化も十分に考慮して、データをどのように使用するか、用途に合わせたスキーマを使用する必要があります。
CassandraへのPagingは実に困難な問題の1つです。たとえLimitというCQL構文があったとしても、文字通り読み込むデータの数を制限する役割に過ぎず、MySQLのLimitのようにOffsetまで処理してくれません。その上、ROW NUMBERのような結果値にナンバリングをする機能さえありません。このような事情から、CassandraでPagingを実装するのは予想以上に簡単ではありません。Partition Key(Row Key)に属するColumnに対するデータがソートされる特性を利用してPagingが可能ですが、Partition Key(Row Key)単位のPagingを実装することは事実上不可能です。理由として、CassandraのPartition KeyはすべてHashingされた結果値に基づいて、データを分散しているからです。
過去にByteOrderedPartitionerを使用していた時代では、まだPartition KeyのPagingが可能でした。すべてのノードに対してPartition Keyの16進数のbyte値の順序通りにデータが分散されていたからです。しかしご存知のように、BOPはHotspotが生じる最大のリスク要因で、代表的なAnti-Patternとして認知されており、現在はMurmur3Partitionerが基本Partitionerとして使用されることによって、すべてのPartition KeyはHashingされた結果値を基準にソートされて格納されています。したがってCassandraで提供されるToken()と呼ばれる特別な関数を用いてHashingされた値の順にデータを読み取ることは可能ですが、続けてデータが追加、変更、削除される度に、データの整列状態が変わることになるので、使用性はあまり高くないでしょう。
とにかく、Keyspace-Table-Row-Columnで階層化されているCassandraでPagingを実装する場合、次の2つに要約できます。
まず、1つのPartition Keyに属するColumnに対するPaging
第2に、複数のPartition Key(Row Key)に対するデータPaging
1つずつ説明します。
CREATE TABLE test_keyspace.test_paging_1 ( class TEXT , name TEXT, description TEXT, PRIMARY KEY (class, name) ); INSERT INTO test_keyspace.test_paging_1 ( class, name, description ) VALUES ( 'junior', 'aron', 'developer' ); INSERT INTO test_keyspace.test_paging_1 ( class, name, description ) VALUES ( 'junior', 'baker', 'developer' ); ... INSERT INTO test_keyspace.test_paging_1 ( class, name, description ) VALUES ( 'junior', 'zena', 'developer' ); SELECT * FROM test_keyspace.test_paging_1;
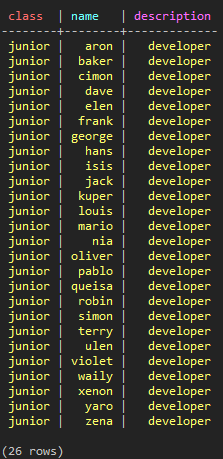 (図20:合計26個のデータが入力された)
(図20:合計26個のデータが入力された)
1つのPartition Key(Row Key)基準に、内部のデータはすでにソートされた状態で存在するため、Limit構文を使って次のようにデータを取得できます。
SELECT * FROM test_keyspace.test_paging_1 WHERE class = 'junior' LIMIT 5;
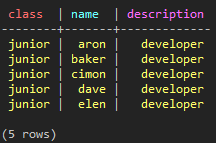 (図21:最初から5つまでのデータを取得)
(図21:最初から5つまでのデータを取得)
その次が問題です。最初の5つのデータを取得しましたが、次の5つのデータはどのように取得すればよいでしょうか?残念ながら、CassnadraのLimitは文字通り読み込むデータの数を制限するだけで、他の機能がありません。したがって、すでに確認している前の5つのデータから、最後のデータに基づいてQueryを作成する必要があります。
SELECT * FROM test_keyspace.test_paging_1 WHERE class = 'junior' AND name > 'elen' LIMIT 5;
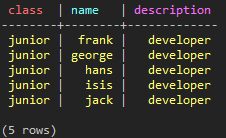 (図22:elenの次に始まるfrankから5つのデータを取得した)
(図22:elenの次に始まるfrankから5つのデータを取得した)
このような方法のPaging方式はいくつか欠点があります。もしRDBMSを使えば内部的にデータをソートし、その結果のidやoffsetを計算して希望する位置のデータだけを切り離してアクセスできます。しかしCassandraの場合はこれらの機能がないため、目的の場所に到達するまでApplicationが直接Cassandraに質疑を続ける必要があります。例えば、最初のページで次に10ページ目の情報を知りたい場合、必要としない9ページの分量を順に読んだ後、10ページ目のデータを取得することができます。さらにこの方法は、Paging対象となるデータ集合の変化に柔軟に対処するのが難しいので、正確なPagingを実装したい場合、毎回データを最初から読み込む必要があります。
 (図23:Paging実装の際、リアルタイムでデータの変更を反映するには、毎回データを最初から読み込む必要がある)
(図23:Paging実装の際、リアルタイムでデータの変更を反映するには、毎回データを最初から読み込む必要がある)
CREATE TABLE test_keyspace.test_paging_2 ( name TEXT, class TEXT ,description TEXT, PRIMARY KEY (name, class) ); INSERT INTO test_keyspace.test_paging_2 ( name, class, description ) VALUES ( 'aron', 'junior', 'developer' ); INSERT INTO test_keyspace.test_paging_2 ( name, class, description ) VALUES ( 'baker', 'junior', 'developer' ); ... INSERT INTO test_keyspace.test_paging_2 ( name, class, description ) VALUES ( 'zena', 'junior', 'developer' );
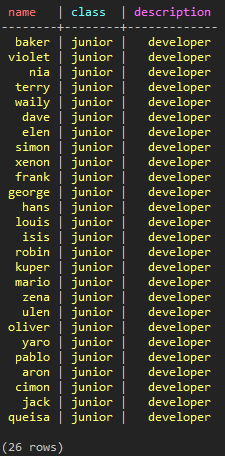 (図24:Partition KeyのHash値を基準として各ノードにデータが分散して保存され、順序が目茶苦茶だ)
(図24:Partition KeyのHash値を基準として各ノードにデータが分散して保存され、順序が目茶苦茶だ)
まず試しに下記のようなQueryを実行してみよう。
SELECT * FROM test_keyspace.test_paging_2 WHERE name > 'elen' LIMIT 5;
![]() (図25:実行されない)
(図25:実行されない)
当然ですが、Queryは失敗します。次に、以下のようにToken()関数を使うと、どうなるでしょうか?
SELECT * FROM test_keyspace.test_paging_2 WHERE token(name) > token('elen') LIMIT 5;
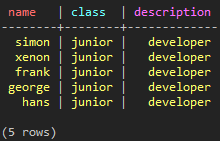 (図26:ソートされた結果でなくてもQueryは実行される)
(図26:ソートされた結果でなくてもQueryは実行される)
ソートされたデータがなくても、希望する5つのデータを取得できます。
このように非常に制限的で貧弱な機能を提供するCassandraですが、多くの方々はこのような状況でも何とか効率的に使用するために、自分なりの方法を絞り出すことでしょう。限定的ですが、上記の2つの方式をミックスしたより良いPagingの実装方法があります。それがPrefixを用いる方法です。
CREATE TABLE test_keyspace.test_paging_3 ( prefix text, remain text, name text, description text PRIMARY KEY ( prefix, body,) ); INSERT INTO test_keyspace.test_paging_3 ( prefix , remain , name, class, description ) VALUES ( 'a', 'ron', 'aron', 'junior', 'developer' ); INSERT INTO test_keyspace.test_paging_3 ( prefix , remain , name, class, description ) VALUES ( 'b', 'aker', 'baker', 'junior', 'developer' ); ... INSERT INTO test_keyspace.test_paging_3 ( prefix , remain , name, class, description ) VALUES ( 'z', 'ena', 'zena', 'junior', 'developer' ); SELECT * FROM test_keyspace.test_paging_3 ;
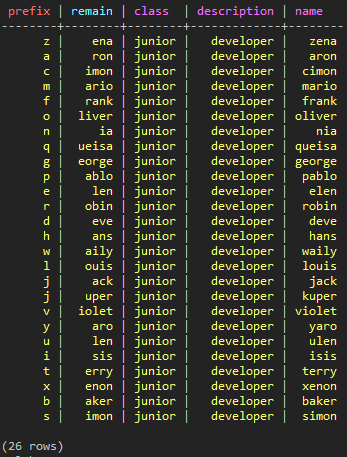 (図27:Prefixを分けてデータを保存した場合)
(図27:Prefixを分けてデータを保存した場合)
このTableを基準に考えてみると、Prefixに基づいてデータが分散され、当該Prefixの中ではremain値にデータがソートされて格納されます。場合によっては有用な手段です。しかし、Shardingを考慮せずにデータを均等に分散するため、Partitionerを使用しているにも関わらず、Prefixを用いることでHotspotが生じる可能性があることを十分に考慮しましょう。
これまでCassandraで一般的に使用されている機能について小さなTipsを紹介してきました。最後になるべく避けるべきCassandraの使用方法について紹介したいと思います。一部は前述したもので、重複する内容は簡略化します。
前章でTime Sequencial DataのCassandraの使い方について調べた内容です。結論から言えば、1つのPartition Key(Row Key)が無限にデータを保存しないということです。この方法は特定のノードにHotsoptを発生させる危険性があり、もう1つのPartition Keyに属するデータが過剰に長くなると、検索のパフォーマンスや適切なQueryの実装にも不利益が生じます。
Secondary IndexはCassandraの不足部分を満たすことができる非常に便利な機能です。しかし、Secondary Indexの濫用は一般的なAnti-Patternとして広く知られています。理由はそれほど複雑ではありません。
CassandraはSecondery Indexのため内部的なTable(ColumnFamily)情報を別に管理しています。そして、特定Tableの特定Columnに対してSecondary Indexを指定すると、当該ColumnのValueをPartition Key(Row Key)としてデータを保存する構造です。簡単に例を挙げてみましょう。下記のようなTableとIndexを作成し、3つのデータを入力してみよう。
CREATE TABLE test_keyspace.test_user (
id TEXT PRIMARY KEY,
name TEXT,
location TEXT
);
CREATE INDEX test_user_idx ON test_keyspace.test_user (location);
INSERT INTO test_keyspace.test_user (id, name, location) VALUES ( 'test_id_1', 'duron', 'seoul');
INSERT INTO test_keyspace.test_user (id, name, location) VALUES ( 'test_id_2', 'frank', 'busan');
INSERT INTO test_keyspace.test_user (id, name, location) VALUES ( 'test_id_3', 'jack', 'seoul');
SELECT * FROM test_keyspace.test_user;
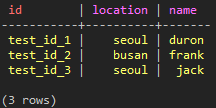 (図28:保存されたデータ)
(図28:保存されたデータ)
Partition Keyにidが指定されたので、上記3データは3つのRowに分かれてデータが保存されています。このときSecondary IndexはCassandra内部で大体下記のようなデータ構造で保存されます。
RowKey: busan => (name=test_id_2:, value=) ------------------- RowKey: seoul => (name=test_id_1:, value=) => (name=test_id_3:, value=)
つまり、Indexに指定したデータをCassandra Data LayerのRow Keyに保有し、当該データの実際のRow Key(上記の例ではid)をColumnにリストのように保有しています。この方式を利用して、CassandraはSecondary Indexで指定されたColumnの値を取得し、その値に属する実際のRow Keyを把握して、各ノードにアクセスしてデータを取得します。
このような構造のため、Secondary Indexで指定されたColumnであってもRange Queryは使用できず、「=」を使った簡易検索やCONTAINSのような文法から、Multi-get形式で一度に様々なColumn Valueの結果をもたらす程度の限定的な機能しか使えないのです。
しかし、最も大きな問題は別にあります。もしSecondary Indexで指定されたColumnにおいて重複する値が非常に長いと仮定しよう。先ほどの例を基準にすると、「seoul」に住んでいるユーザー数が非常に多い場合にあたるでしょう。Secondary Indexの「seoul」というRow Keyの下に多くのユーザーidがぶら下がっているという話です。「seoul」に属するデータを取得するには、多くのidが格納されたCassandraのノードにすべてアクセスすることになります。もし「seoul」に属するidが極めて多ければ、最悪の場合はCassandraに属するノードのすべてがビジーな状態に陥るでしょう。さらにConsistancy Levelに合わせて、各データのReplicationも確認する必要があります。
したがってSecondary Indexの使用は慎重に決定する必要があり、非正規化は依然として多くの人々に愛されるCassnadra Data Modeling手法の1つとして存在しています。
TombstoneはCassandraが持つかなり特徴的なものの1つです。前回の記事で説明したように、Cassandraは基本的にDataのDeleteを即時実行せずに、Tombstoneと呼ばれるmarkerに表示しておき、SSTableのcompactionが進行したとき、初めてデータが削除されるという構造を持っています。一見すると、効率的かつ合理的な構造だと言えますが、リアルタイムでデータを削除しないこの原則によって、予期しない副作用が発生するようになりました。
まずは削除されたデータが復活する問題です。これは時をわきまえず、データが復活するという意味ではありません。
これは障害が発生したノードが正常化し、Ringに復帰したときに発生することがあります。
Cassandraのいずれかのノードで障害が発生した場合を想定してみましょう。障害ノードはダウンして使用できませんが、他のノードは正常に動作しています。そのうち多くのデータに変更が生じますが、その中に削除すべきデータがあった場合、他の正常な状態のノードでは、すでに正常に削除されており、何の痕跡も残らないでしょう。このとき障害ノードが障害から抜けて、Ringに復帰するとどうなるでしょうか。障害ノードは、これまであったデータの変更点を反映するために、他のノードとGossip Protocolを用いてデータの復旧を開始します。変更されたデータがあれば最新に更新して、新しいデータがあればコピーして取得します。問題は、この過程で自分が所持していた他のノードで既に削除されたデータを復元してしまう状況が発生します。他のノードには既に存在しないデータですが、論理的に見たときは自分だけが持っていてもこれは正常なデータであるため、Replicationはこれを満たすために他のノードにデータをリライトしてしまうのです。
Cassandraのconf/cassandra.yamlを確認すると、gc_grace_secondsというオプションを確認できますが、これは複数ノードで構成されたRing構造で互いにデータの削除可否に対する状態を安全に伝播するためtomstoneのgarbage collecting周期を設定するオプションです。死んだデータが生き返る、このような問題を防ぐためにはgc_grace_secondsのオプションを慎重に決定し、障害ノードのリカバリポイントをgc_grace_secondsを超過しないように努めます。もしgc_grace_seconds周期が過ぎた時点で、障害ノードが復旧していたら、他の正常なノードは高い確率でcompactionを通じてデータをすべて削除していたでしょう。
2つ目はReadパフォーマンスの問題です。
CassandraはTombstoneを利用してデータの削除を管理するという特徴のほかに、すべてのデータをSequencialに保存する機能も持っています。要約するとMemtableやSSTableの前に保存されたデータがDeleteの状態になっても、Tombstoneがmarkingされるだけで、実際にはcompactionが起きるまで、依然としてDiskに存在している状態であるということです。したがってSSTableのデータをSequencialで読ま必要があれば、Cassandraの立場ではすでにTombstoneにmarkingされているデータであったとしても、ひとまず読み込みます。これはかなり重要な部分で、Cassandraを絶対Queueのような方式では使用してはいけないという根拠になります。
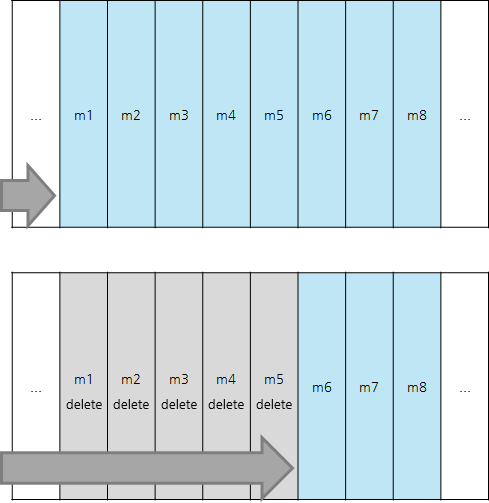 (図29:前のデータが削除されてもすべて確認して次に移動する)
(図29:前のデータが削除されてもすべて確認して次に移動する)
1つのRowをQueueに見て、当該RowにColumnをMessageのように順番にWriteする状況を想定してみよう。Messageを消費すると前のデータは順番にTombstoneが記録されます。ところがCompactionによってデータが消える前に膨大な量のMessageが入ってきて消費されたとしたら?消費されたMessage Dataは単にTombstoneが記録されているだけで、依然として残っている状態です。このとき新しいメッセージを取得しようとすると、まだ残っているMessage Dataのあるところまで前のTombstone Dataを全て経る必要があります。当然速度は遅くなるでしょう。
これは単にQueueで使ったときに限定されるものではありません。大量のデータを頻繁に更新・削除すれば、当然、当該Rowの読み取り性能は落ちるでしょう。したがってCassandraのスキーマを設計するためには、当該データをどのように使用するか十分に検討した上で反映するように努力すべきでしょう。
Cassandraは毎回Hashingを通じて計算されるRow Keyとは異なり、すべてのKeyspaceとTableに対するMetadataをJVMメモリに置いて使用しています。これは分散されず、Ringを構成するすべてのノードが同一に持っているデータです。つまり、あまりにも多くのKeyspaceとTableを作成するとMemoryが急激に排出されることがあります。必要に応じて毎回TableまたはKeyspaceを生成する方法でCassandraを使用すると、Memory OverflowによってCassandraノードが死んでしまう現象が発生することがあるので、このような使用方法は必ず避けるべきでしょう。
Cassandraを使用する場合にこれだけ知っておきたいという内容を中心に整理しました。少し長くなってしまいましたが、この記事が少しでも役立つと幸いです。

NHN Cloud Meetup 編集部